Benchmarks
Does it actually work? We ran the numbers.
5 benchmark runs · 80+ prompts · real 92-file production codebase · same model (Claude Sonnet 4.6), same questions — with and without GrapeRoot.
GrapeRoot 4-Way Pro — GR v3 vs Boris CLAUDE.md vs JCM vs Normal
NEW4-way · 30 code-audit prompts · Medusa e-commerce (~1,571 TypeScript files, 4 packages) · Claude Sonnet 4.6 · LLM judge
The question we asked
Boris Cherny — creator of Claude Code at Anthropic — publicly shared his CLAUDE.md methodology: plan before you search, run verification loops, iterate until coverage is complete. Does this approach, with no special tools, beat purpose-built MCP code-search tools on real audit tasks?
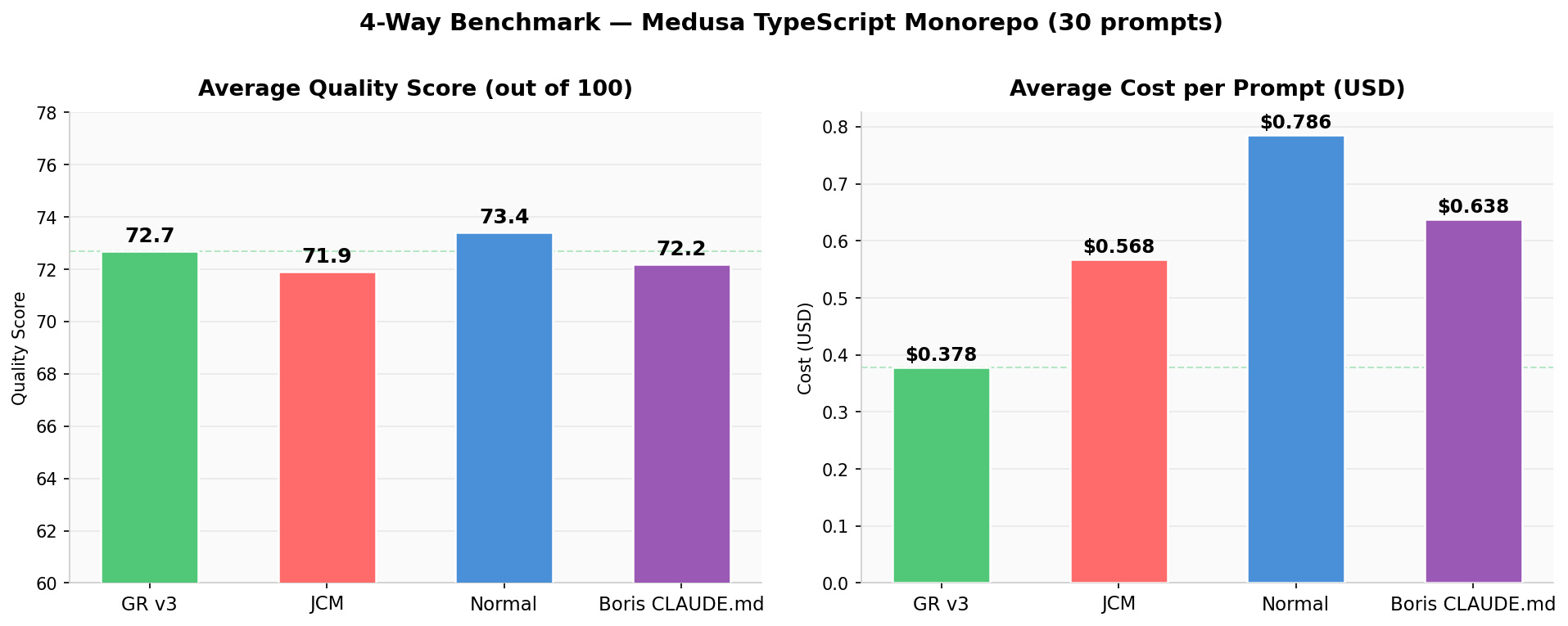
GR v3
72.7
avg quality / 100
Boris CLAUDE.md
72.2
avg quality / 100
JCM
71.9
avg quality / 100
Normal
73.4
avg quality / 100
Key Finding
GR v3 is the cost efficiency winner. Boris CLAUDE.md has the highest quality — at 70% more cost.
Why GR v3 wins overall
- $0.374/prompt — cheapest by a wide margin
- AST index delivers precision with zero wasted greps
- Consistent across all 4 task categories
- Fastest execution — avg wall time competitive
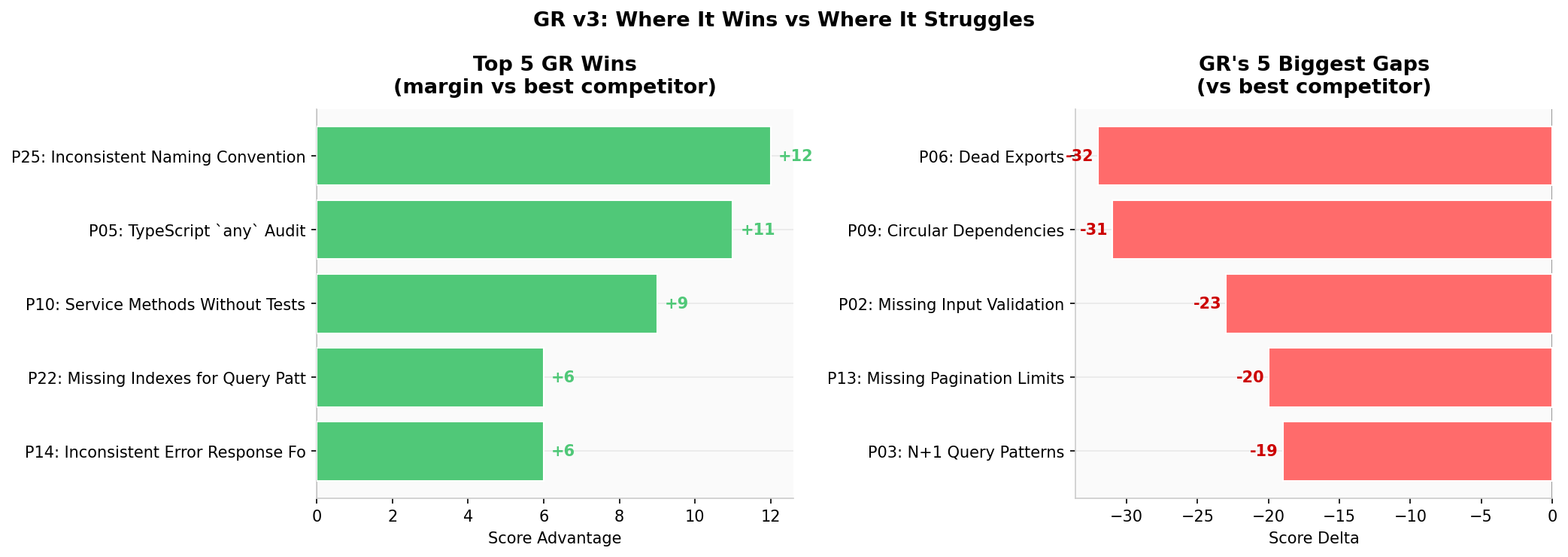
- Unique wins: Rate Limiting +5 vs field, TypeScript any +11 vs Boris
Where Boris CLAUDE.md surprised
- Highest avg quality (72.2) of all 4 modes
- P06 Dead Exports: Boris=69, JCM=85, Normal=82, GR=53 — exhaustive full-codebase scan
- P16 Privilege Escalation: Boris 86 (best)
- P28 CORS Config: Boris 88 (best, +18 vs GR)
- Plan-first methodology genuinely helps on reasoning-heavy tasks
Featured Chart
Analytics — 13 Charts
Summary: Quality & Cost
Side-by-side avg quality score and cost per prompt across all 4 modes
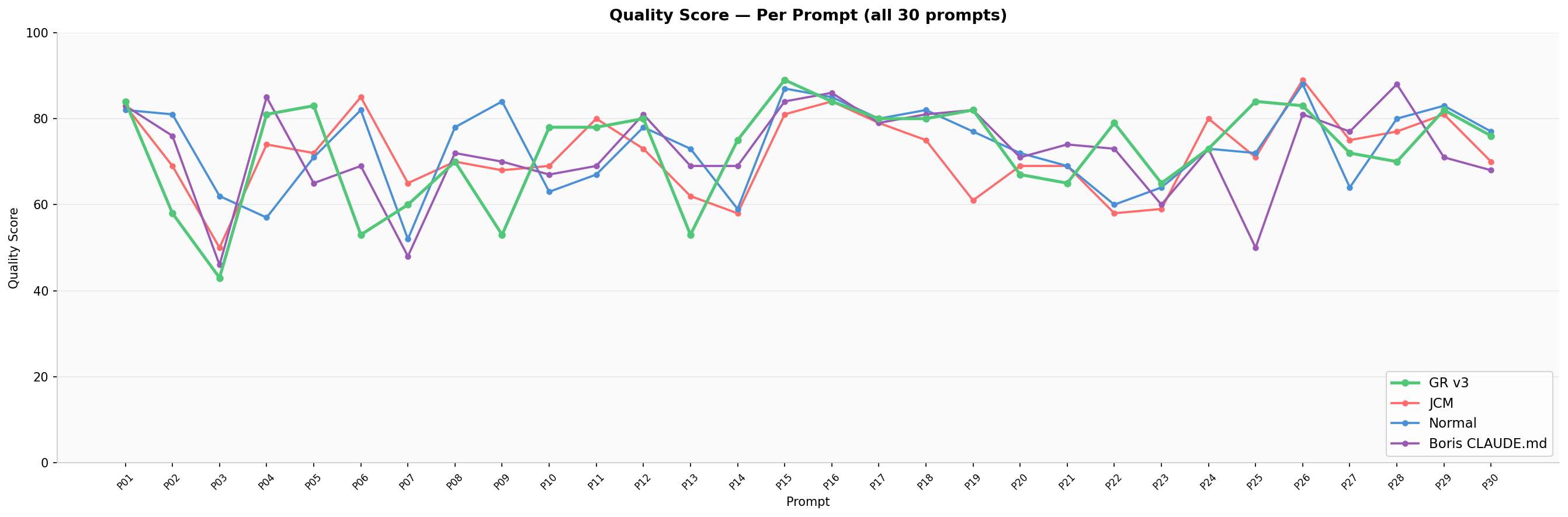
Per-Prompt Quality (all 30)
Line chart showing every prompt's quality score — GR is consistently competitive
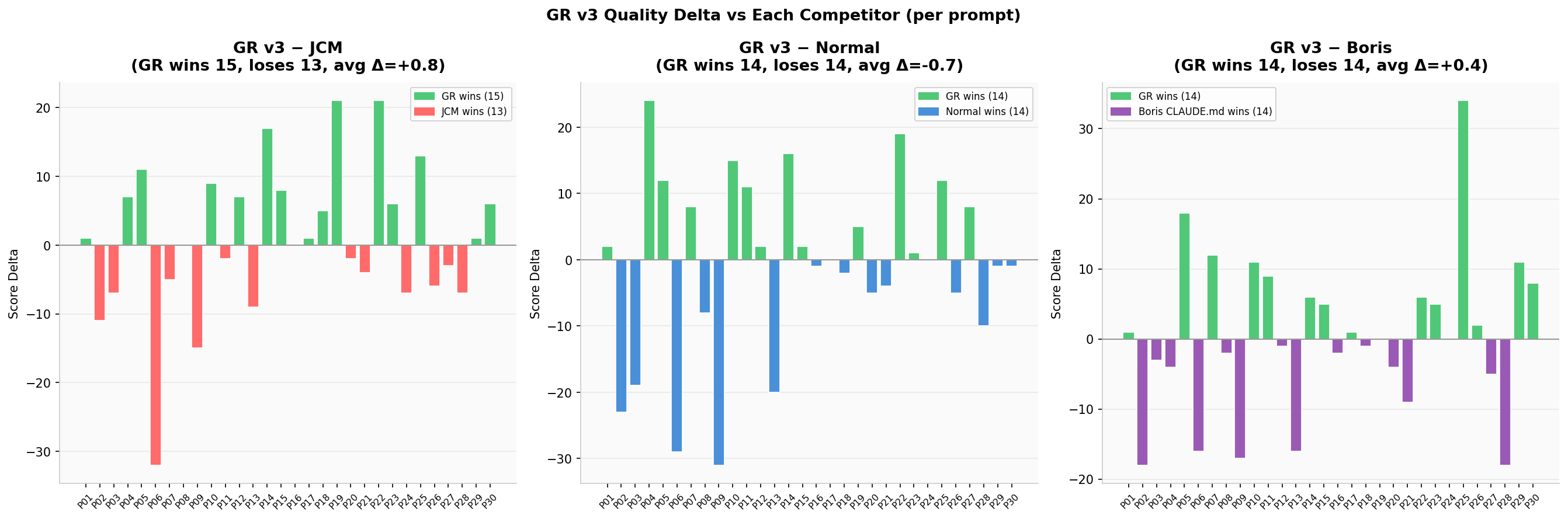
GR Delta vs Each Competitor
Bar chart: GR score minus competitor score per prompt — green = GR wins
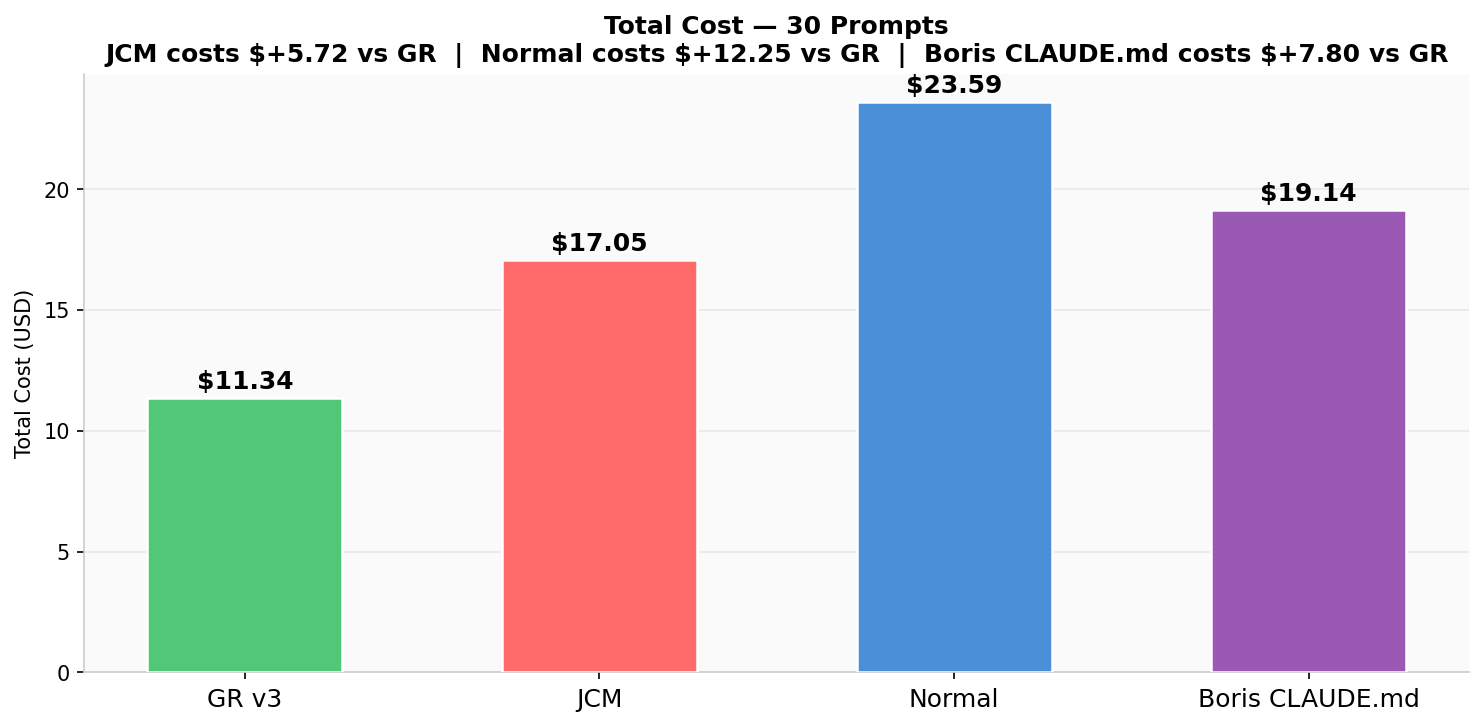
Total Cost — 30 Prompts
GR $11.34 total vs Boris $19.14, JCM $17.05, Normal $23.59
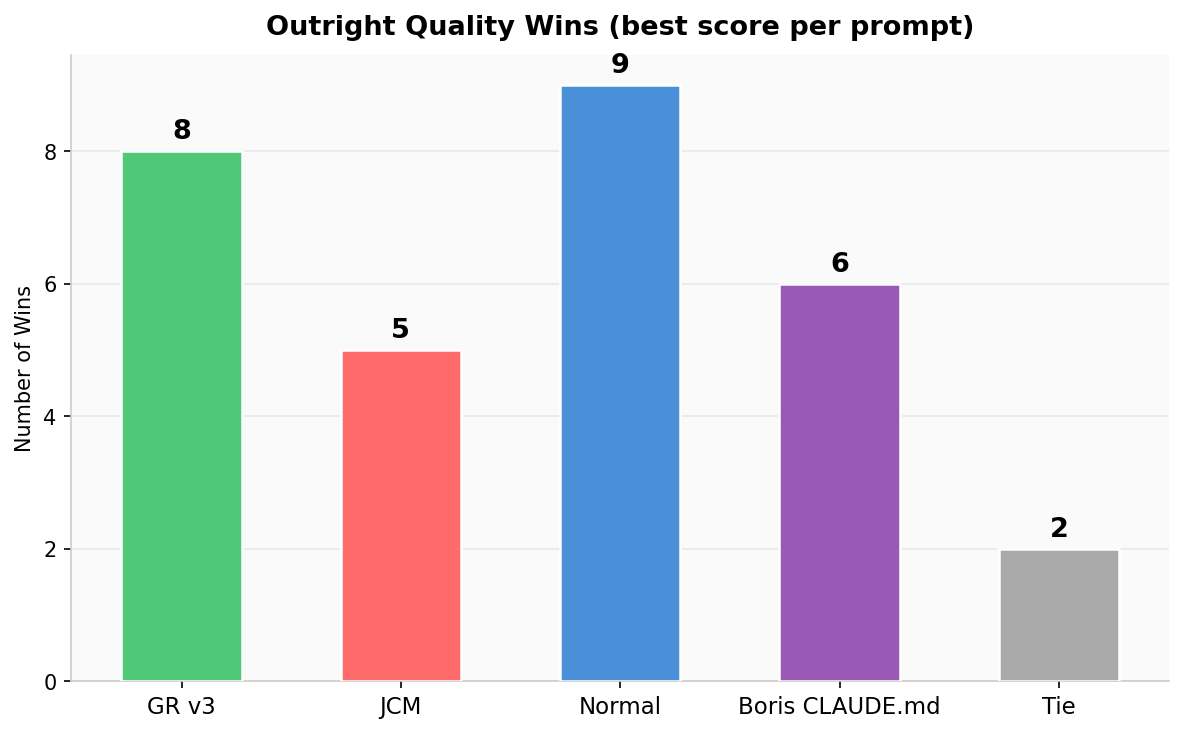
Outright Quality Wins
Prompts where each mode scored highest — GR 8, Normal 9, Boris 6, JCM 5
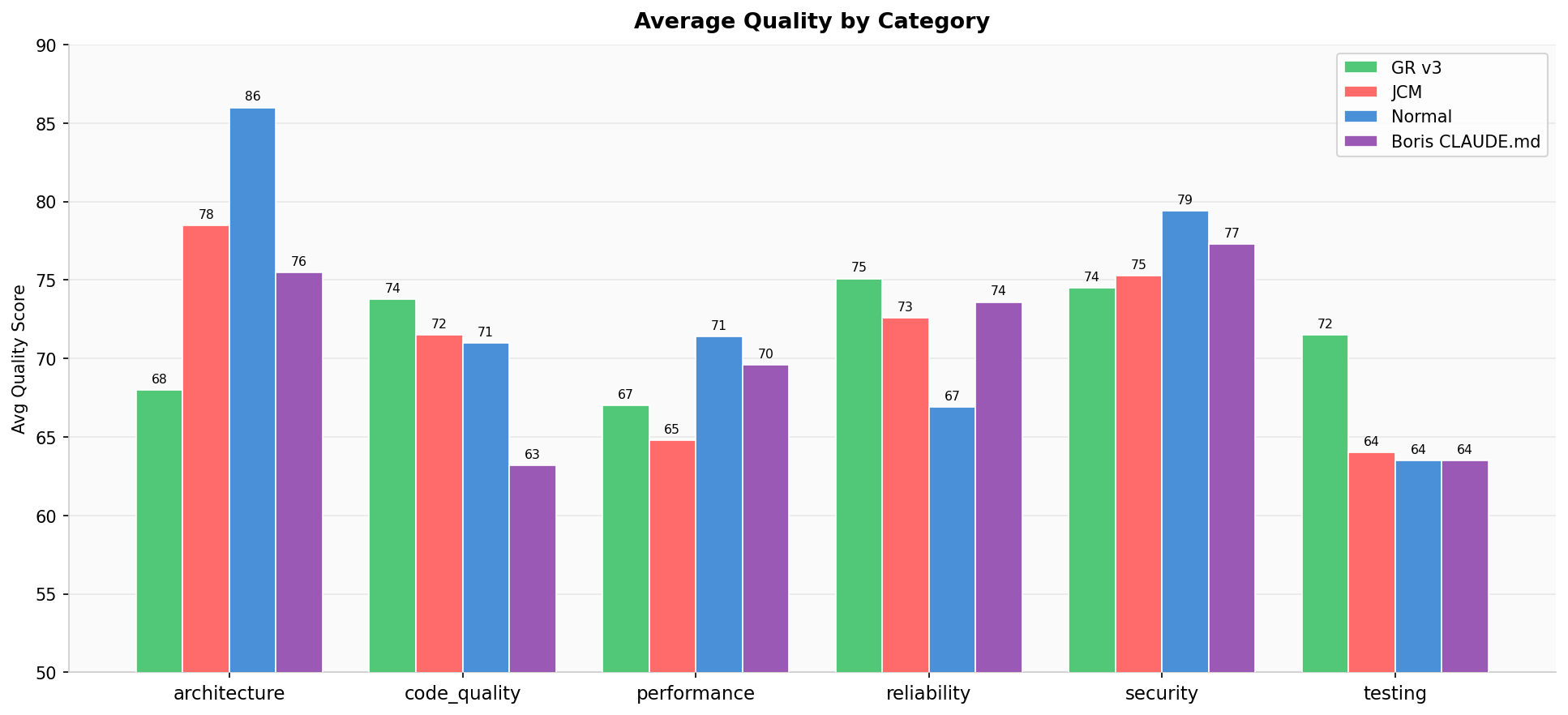
Quality by Category
Grouped bar chart across security, performance, reliability, maintainability
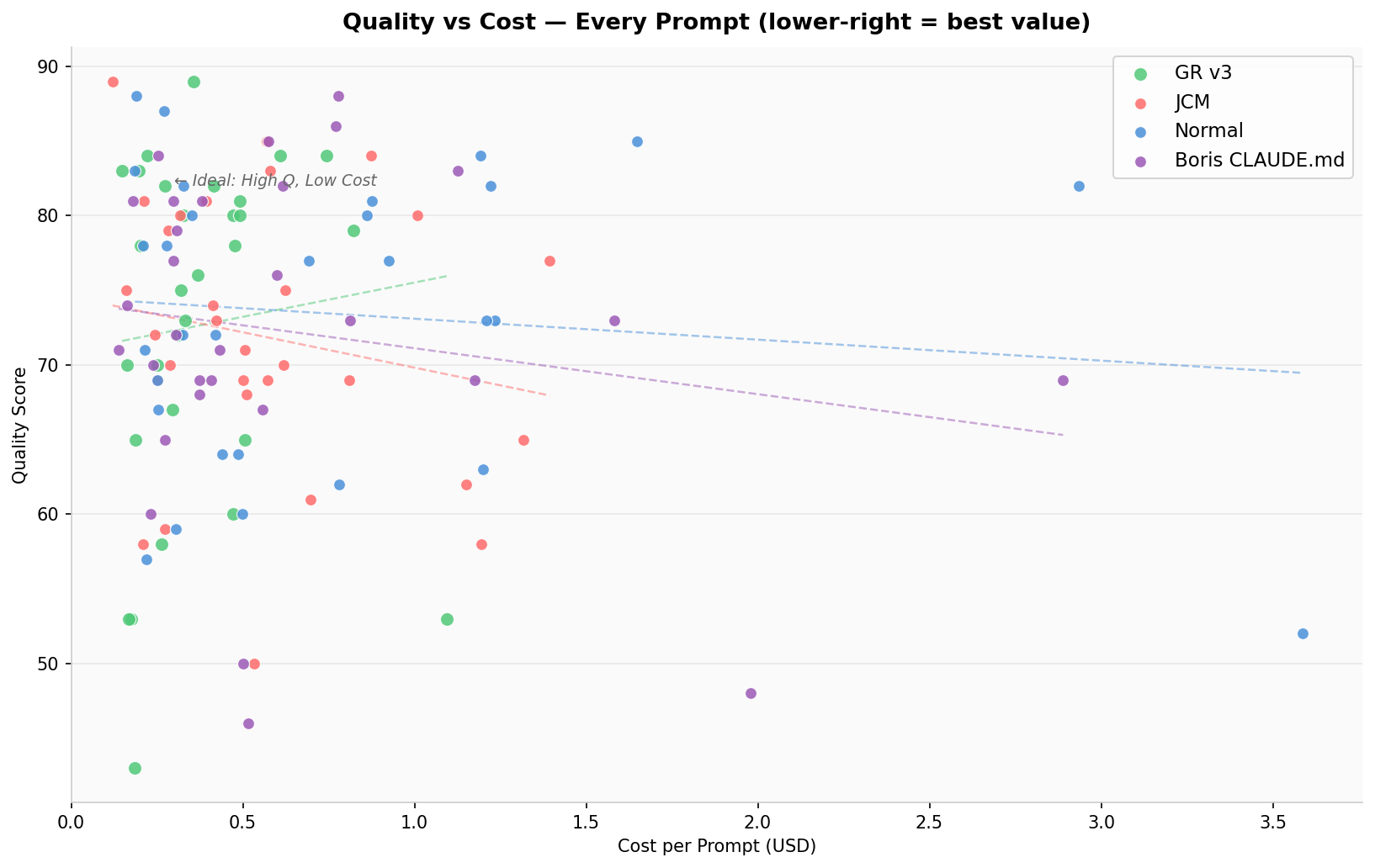
Quality vs Cost Scatter
Every prompt plotted — GR clusters bottom-right (high Q, low cost)
GR Strengths & Gaps
Top 5 GR wins and bottom 5 gaps vs best competitor
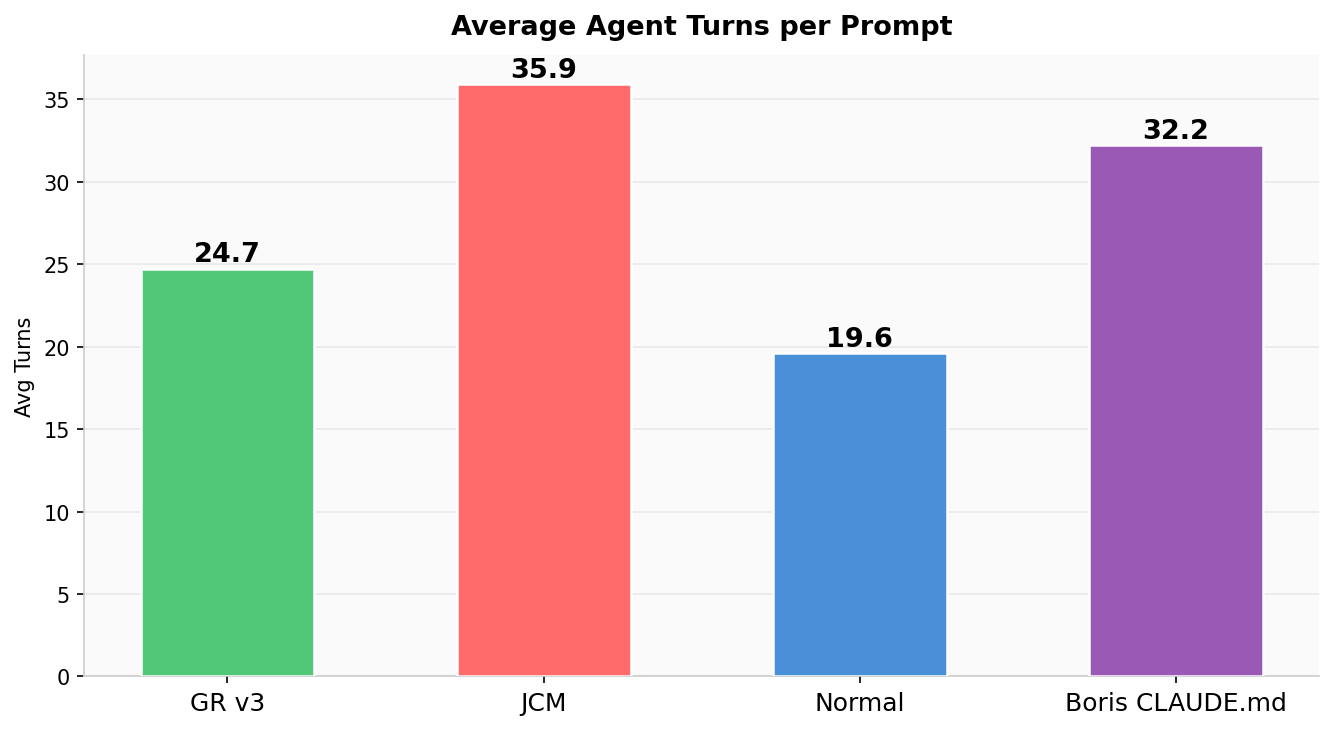
Avg Wall Time per Prompt
Seconds per prompt — GR and JCM are fastest
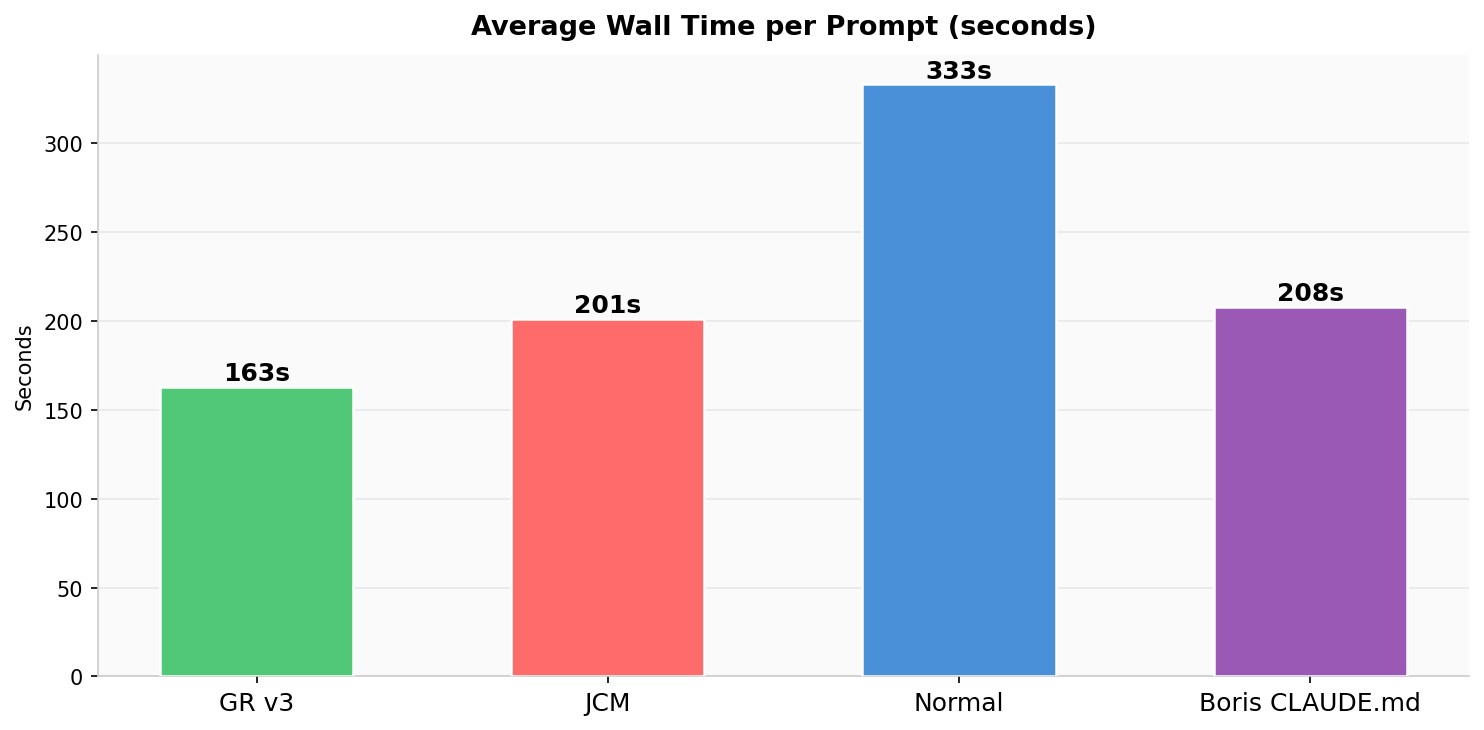
Quality Dimensions Radar
5 LLM judge sub-scores overlaid: findings accuracy, coverage, depth, fix completeness, actionability
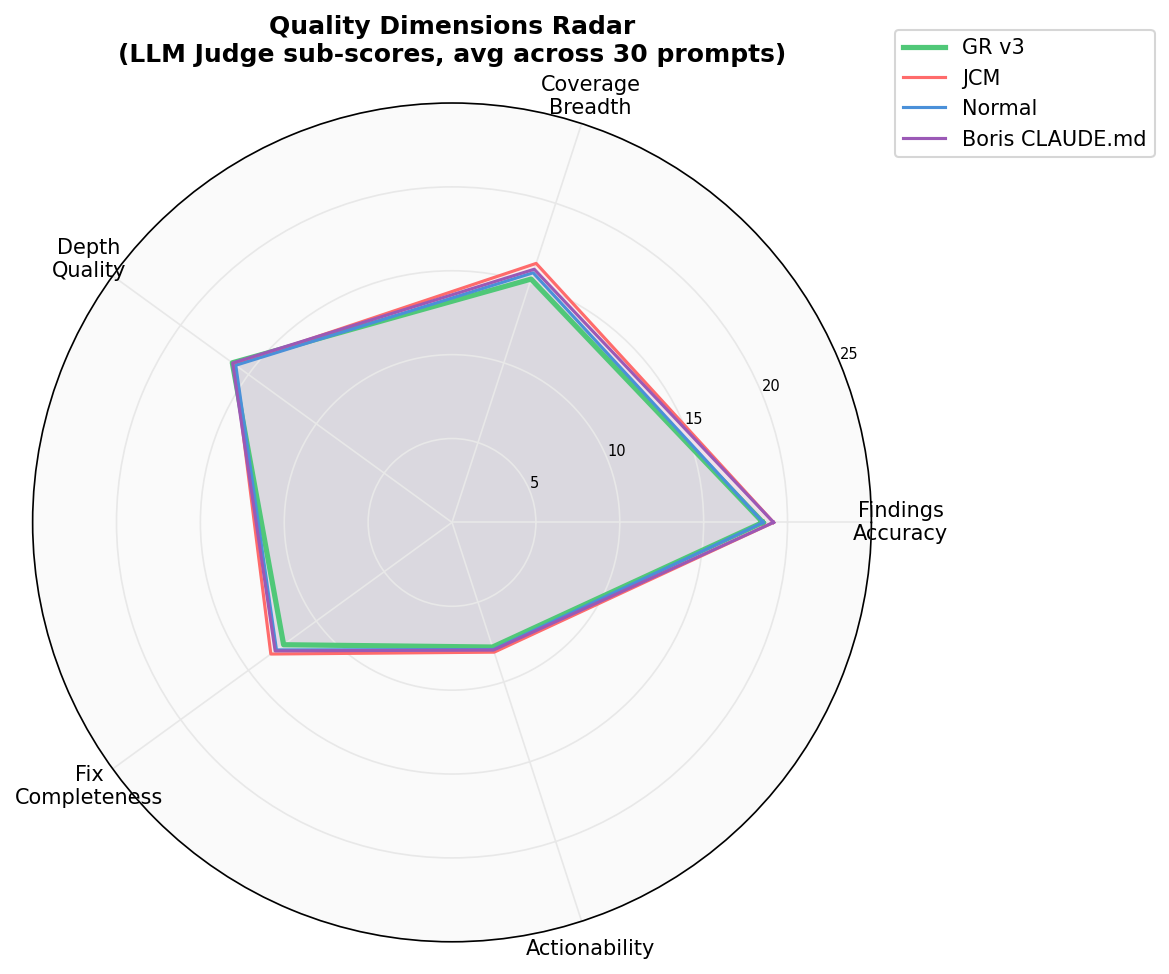
Cost vs Agent Turns
More turns = more cost. GR stays efficient even at high turn counts; Boris and JCM trend expensive
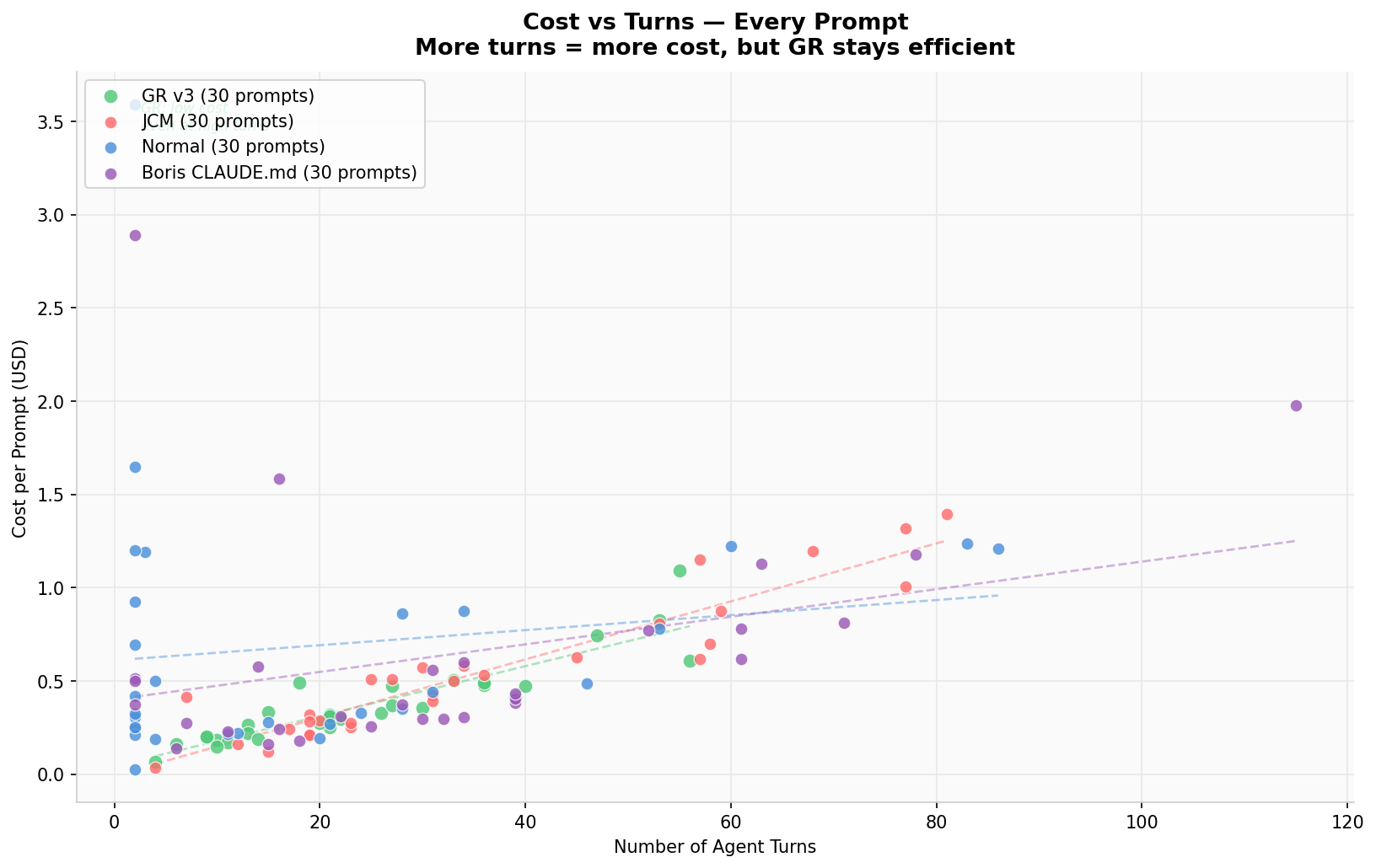
Average Turns per Prompt
GR: 24.7 avg turns · Boris: 32.2 · JCM: 35.9 · Normal: 19.6 — GR does more with fewer turns
GR v3 — Known Gaps
Pattern: GR underperforms when tasks require enumerating every file rather than retrieving the most relevant K files.
Boris Cherny's CLAUDE.md (tested)
# Boris Cherny's Methodology — Benchmark Policy > Enterprise TypeScript monorepo (~1571 source files). > No MCP tools. Use bash: grep, find, cat, head. ## Step 1: Plan before you search (mandatory) Before running any grep or reading any file: 1. Break the task into sub-questions 2. List relevant packages and file patterns 3. Decide search terms upfront (primary + 2-3 alternatives) 4. Then execute the plan ## Step 2: Search systematically - Use `grep -rn` to search with line numbers - Check ALL 4 packages: medusa, admin, cli, plugins - Run multiple searches — first search rarely catches everything - For exhaustive tasks: minimum 3 grep passes ## Step 3: Verification loop After initial findings, ask yourself: - "What search terms did I miss?" - "Did I check all packages?" - "Are there 5+ instances or did I stop too early?" Run 1-2 more targeted greps to verify completeness. ## Things you must NOT do - Don't stop after 1-2 examples when asked to find ALL instances - Don't skip the planning step - Don't report without specific file:line citations _Every missed instance is a gap. Iterate until coverage is complete._
Methodology
# Codebase: Medusa e-commerce monorepo
# ~1,571 TypeScript source files, 4 packages
# Repo: github.com/medusajs/medusa (open source)
# 4 isolated worktrees — no shared state:
# medusa-gr-final/ → GR v3 (AST index, graph_continue → graph_read)
# medusa-jcm/ → JCM (jcodemunch-mcp, SSE port 8201)
# medusa-normal/ → Normal (bash/grep only)
# medusa-boris/ → Boris (bash/grep + Boris CLAUDE.md)
# Per prompt — all 4 modes run simultaneously:
with ThreadPoolExecutor(max_workers=4) as pool:
futures = {pool.submit(run_mode, mode, prompt): mode
for mode in ["gr","jcm","normal","boris"]}
# Each mode call:
result = subprocess.run(
["claude", "-p", prompt,
"--model", "claude-sonnet-4-6",
"--dangerously-skip-permissions",
"--no-session-persistence",
*mcp_flags], # only set for gr/jcm
cwd=worktree_path,
timeout=None # no timeout — some prompts take 10+ min
)
# LLM judge — 5-dimension rubric (100 pts total):
# findings_accuracy /25 — real file paths, real line numbers?
# coverage_breadth /25 — all 4 packages checked?
# depth_quality /20 — explains WHY each issue is a problem?
# fix_completeness /20 — all instances found, not just first few?
# actionability /10 — can a dev act on this immediately?
# Cost calculation (cache-filtered):
cost = (
(input_tokens - cache_read - cache_write) * 3.00/1M
+ cache_write_tokens * 3.75/1M
+ cache_read_tokens * 0.30/1M
+ output_tokens * 15.00/1M
)Codebase Used
Language
TypeScript
Source files
~1,571
Packages
medusa · admin · cli · plugins
Framework
Express / NestJS
GR index
AST · 3,712 symbols
Prompts
30 code-audit tasks
Categories
security · perf · reliability · maint.
Avg turns (GR)
24.7 turns · max 56
Codebase repo (open source)
github.com/medusajs/medusa ↗Benchmark run March 2026 · Claude Sonnet 4.6 · 30 code-audit tasks on Medusa (~1,571 TypeScript files) · LLM judge: Claude Sonnet 4.6 · 4-way comparison (GR v3 / JCM / Normal / Boris CLAUDE.md) · isolated git worktrees per variant · GR AST index pre-built (3,712 symbols).