Benchmarks
Does it actually work? We ran the numbers.
5 benchmark runs · 80+ prompts · real 92-file production codebase · same model (Claude Sonnet 4.6), same questions — with and without GrapeRoot.
Sentry Python Benchmark
30 prompts · getsentry/sentry · ~7,762 Python files · Django + Celery + Snuba · GR v3 vs Normal · community challenge open
All costs = Anthropic API charges · Claude Sonnet 4.6 (main agent) + Claude Haiku 4.5 (subagents spawned by Normal mode)
getsentry/sentry
github.com/getsentry/sentry ↗Open-source error tracking · Python/Django · ~7,762 Python files · Celery + Snuba · REST API + ORM + integrations
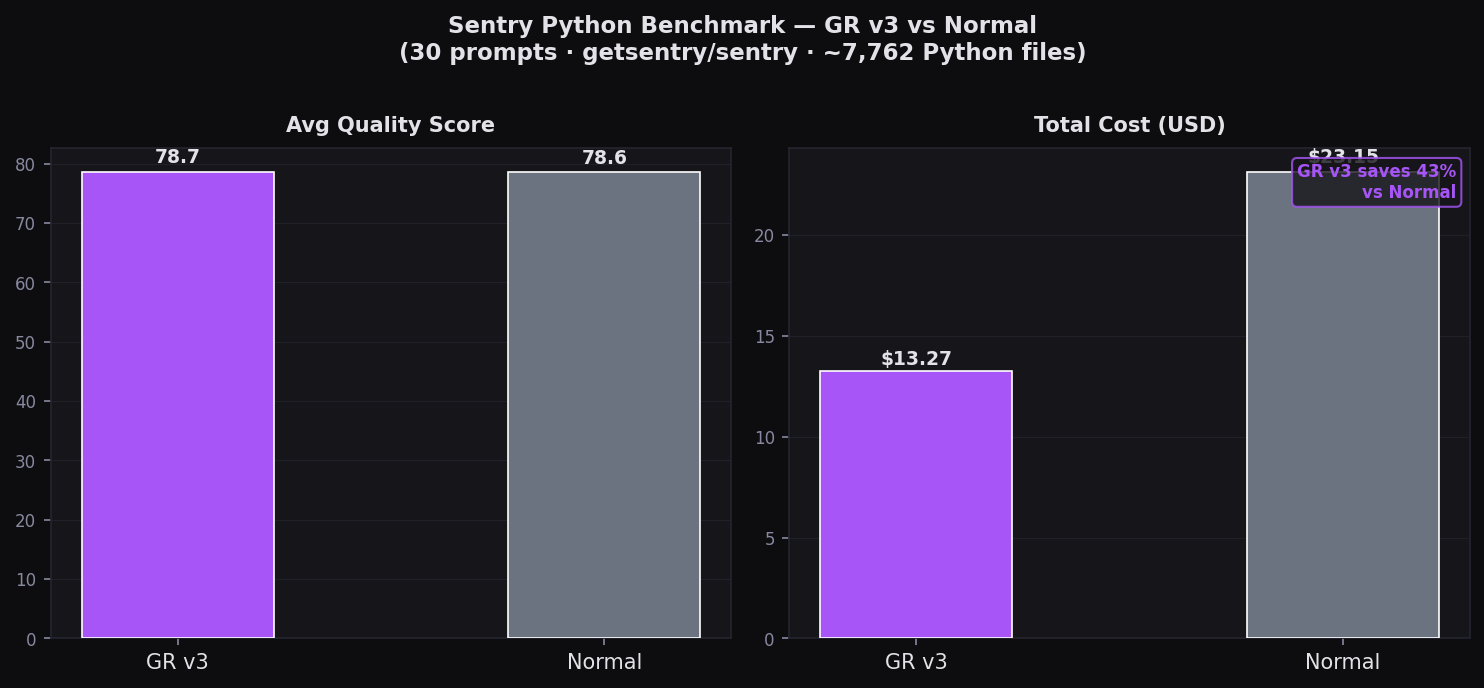
78.4/100
GR v3 avg quality
78.6/100
Normal avg quality
43%
API cost saved vs Normal
$13.25
GR v3 API cost (30 prompts)
Costs = Anthropic API charges only (input + output + cache tokens). Normal mode spawns multiple Claude Haiku 4.5 subagents for search/grep operations — those API calls are included. GR v3 uses Claude Sonnet 4.6 exclusively. Same model, same prompts, same codebase.
Same quality. 43% cheaper in API costs.
At 7,762 files — the largest codebase tested — GR v3 totalled $13.25 in Anthropic API charges vs Normal's $23.14 — a 43% reduction at near-equal quality (78.4 vs 78.6/100). Normal's higher cost comes from the Haiku 4.5 subagents it spawns for bash/grep search passes — each prompt triggers multiple tool-use rounds that add up fast on a 7,762-file codebase. Think your setup can beat GR v3? Run the prompts and submit.
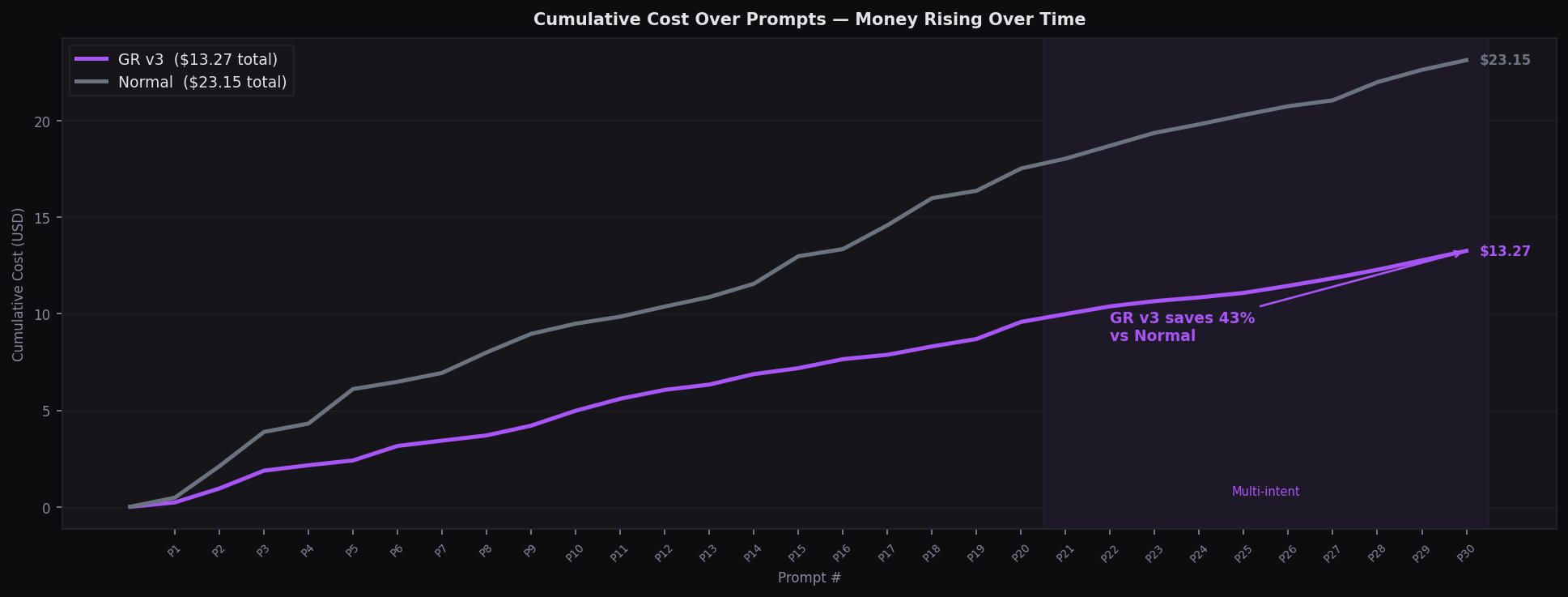
Featured — Cumulative Cost
Cumulative Cost — Watch the Money Add Up
GR v3: $13.25 · Normal: $23.14 — 43% cheaper at equal quality · 30 prompts
All Charts
Summary: Quality & Cost
Avg quality and total cost — GR v3 vs Normal across 30 prompts
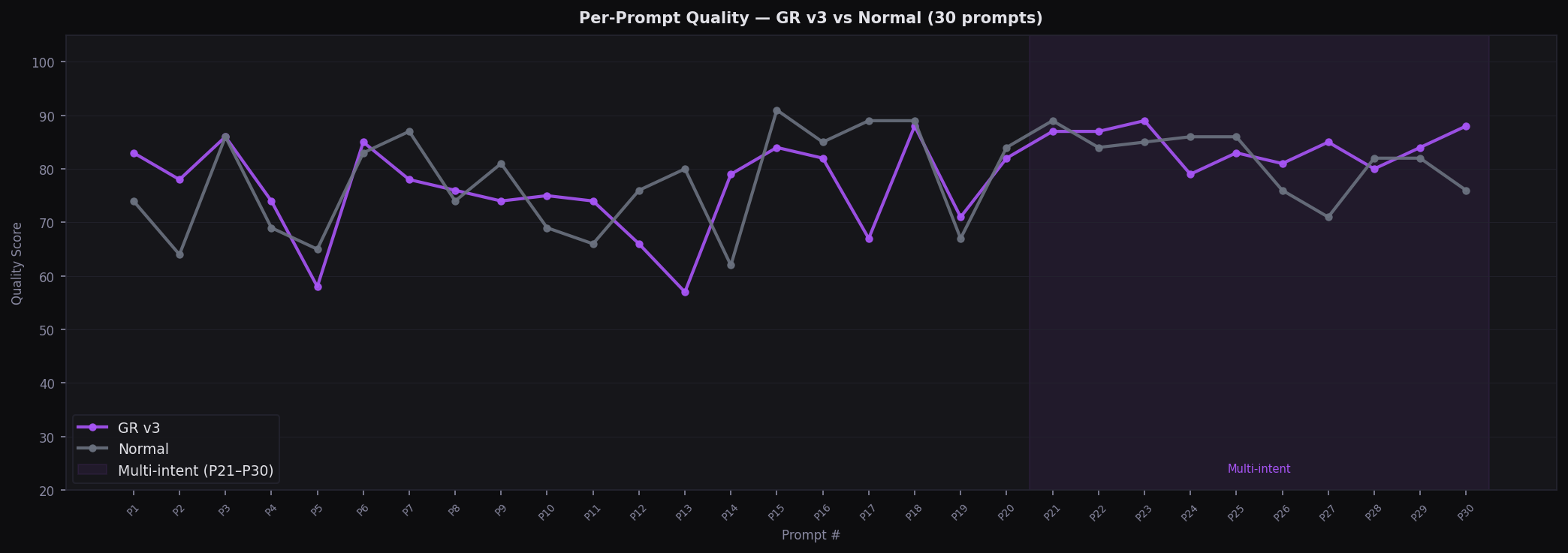
Per-Prompt Quality (all 30)
Line chart — every prompt quality score; MI region highlighted P21-P30
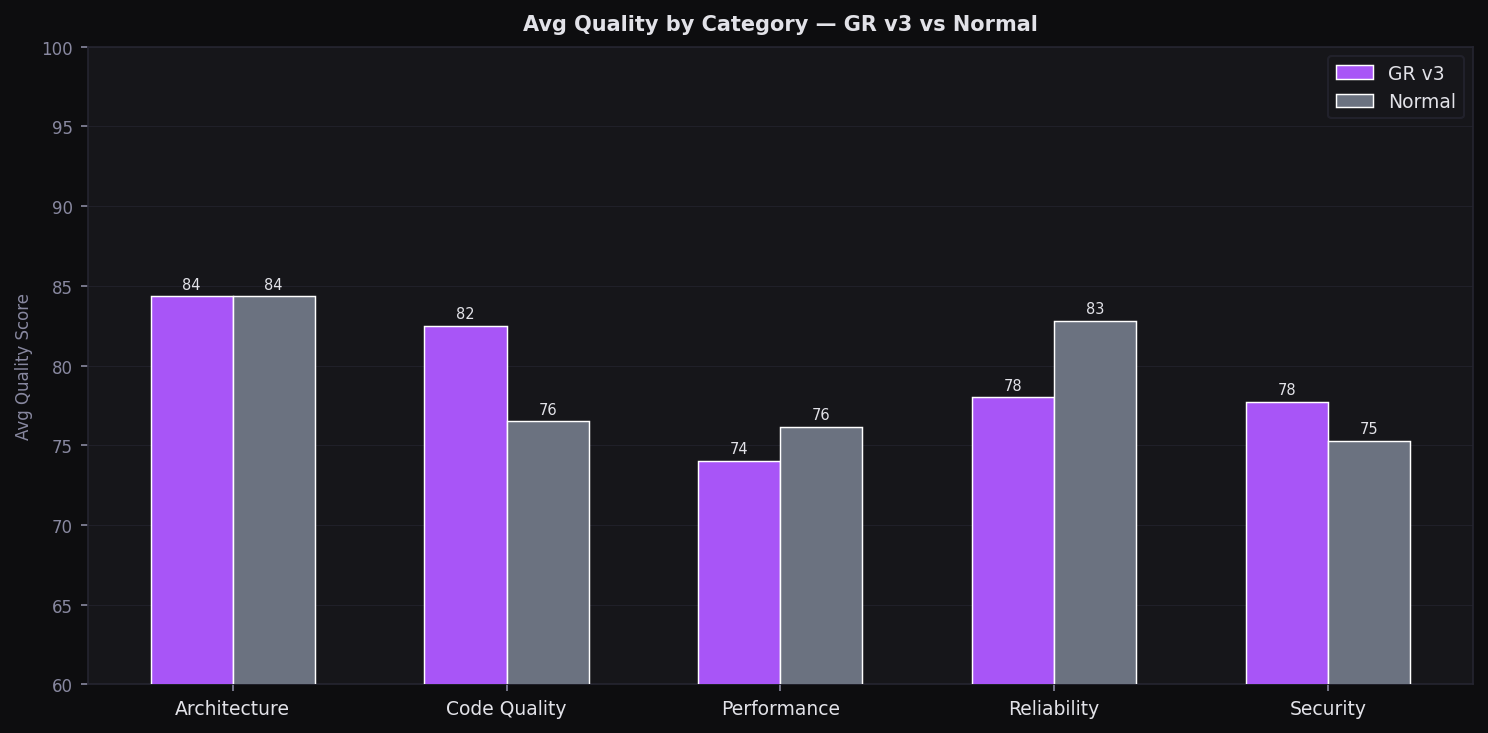
Quality by Category
GR v3 leads on architecture & code quality; Normal competitive on reliability
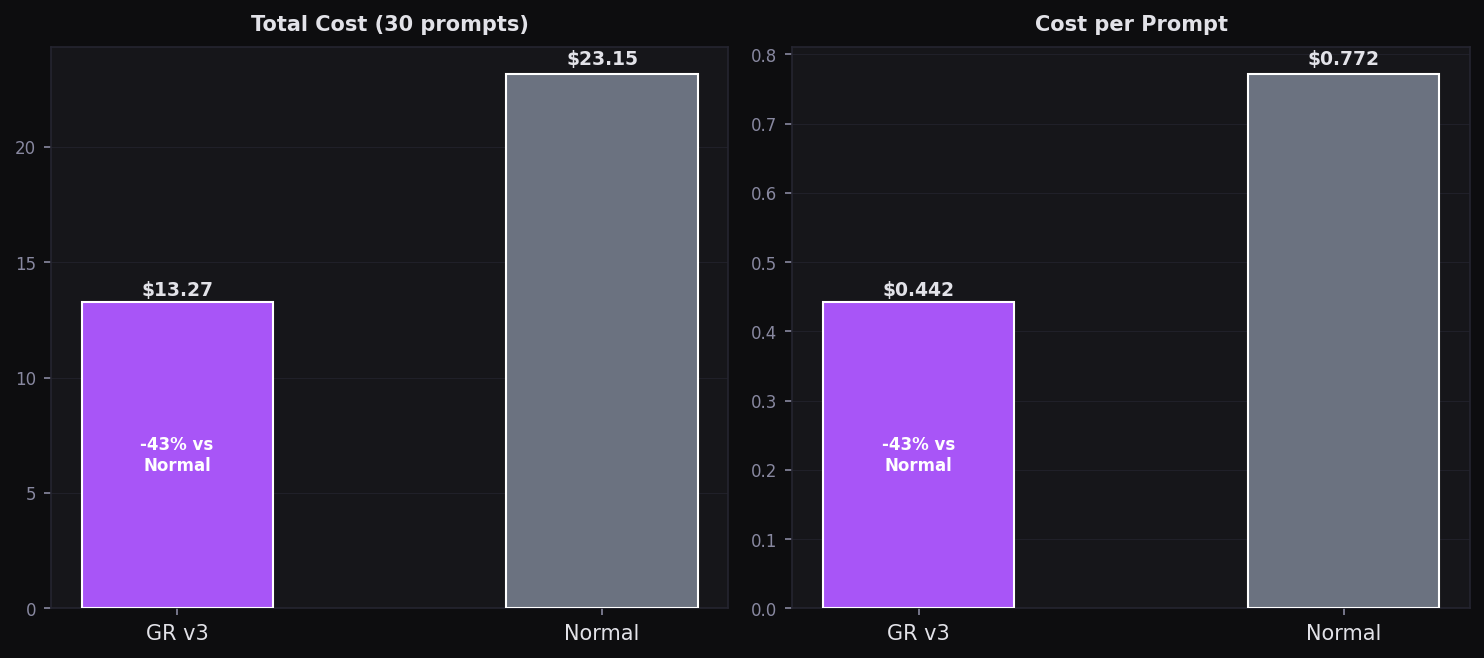
Total Cost — 30 prompts
GR v3: $13.27 vs Normal: $23.15 — 43% cheaper at equal quality
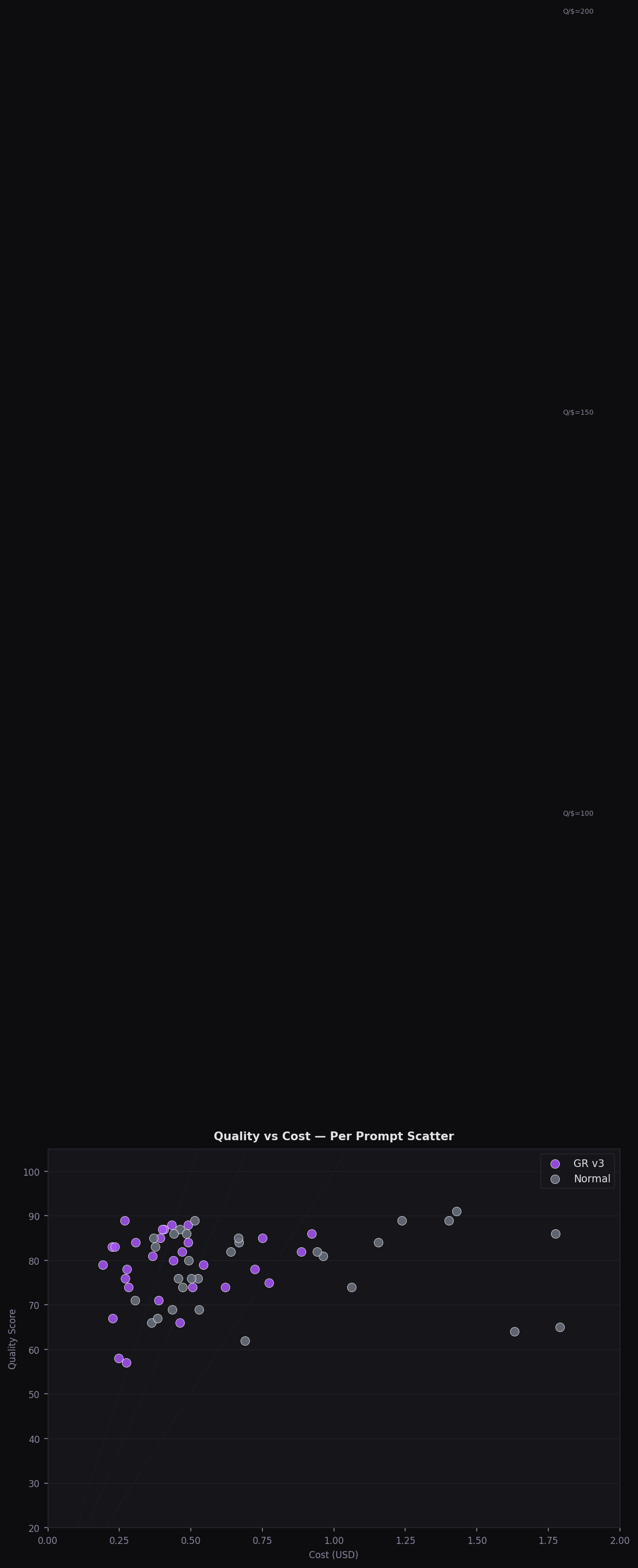
Quality vs Cost Scatter
Every prompt plotted — GR v3 clusters bottom-right (high Q, low cost)
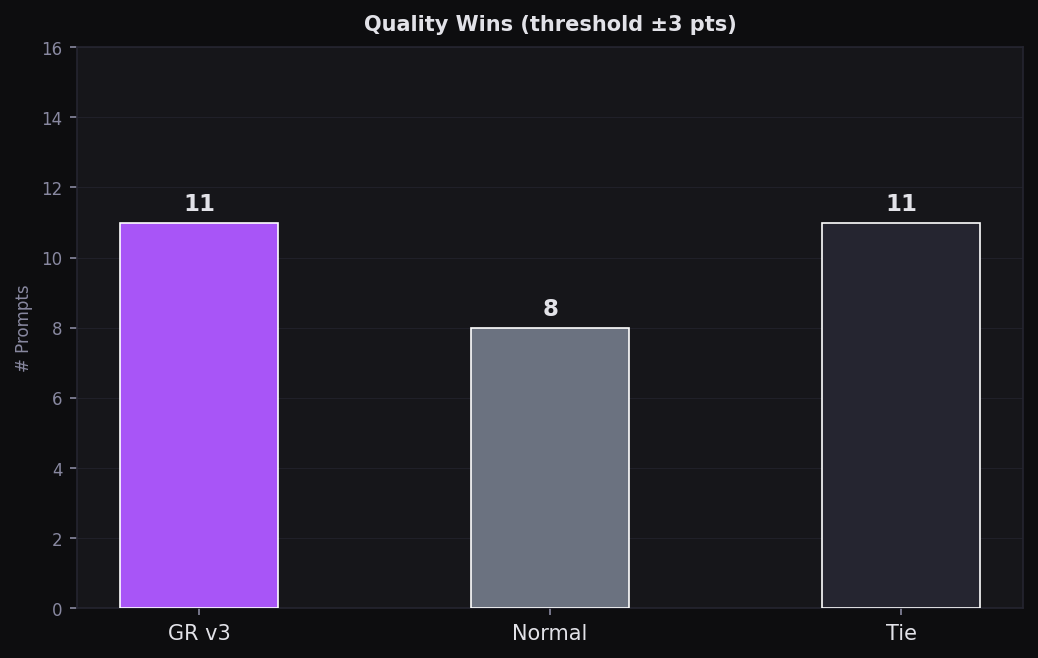
Value Wins per Mode
Prompts where each mode had best Quality÷Cost ratio
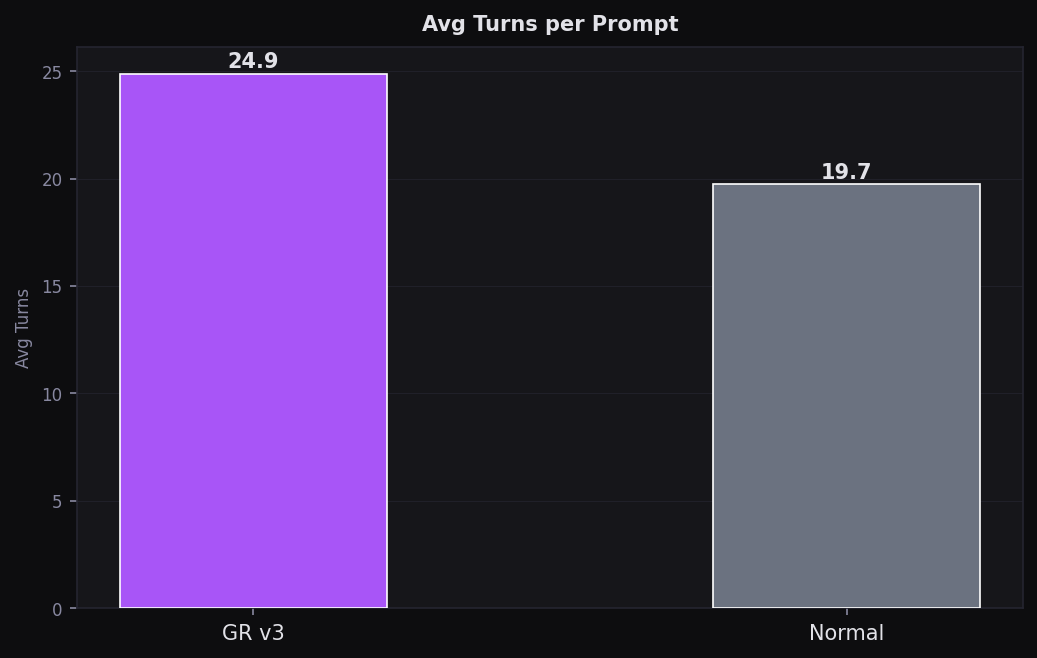
Avg Turns per Prompt
GR v3 uses fewest turns — efficient retrieval means less back-and-forth
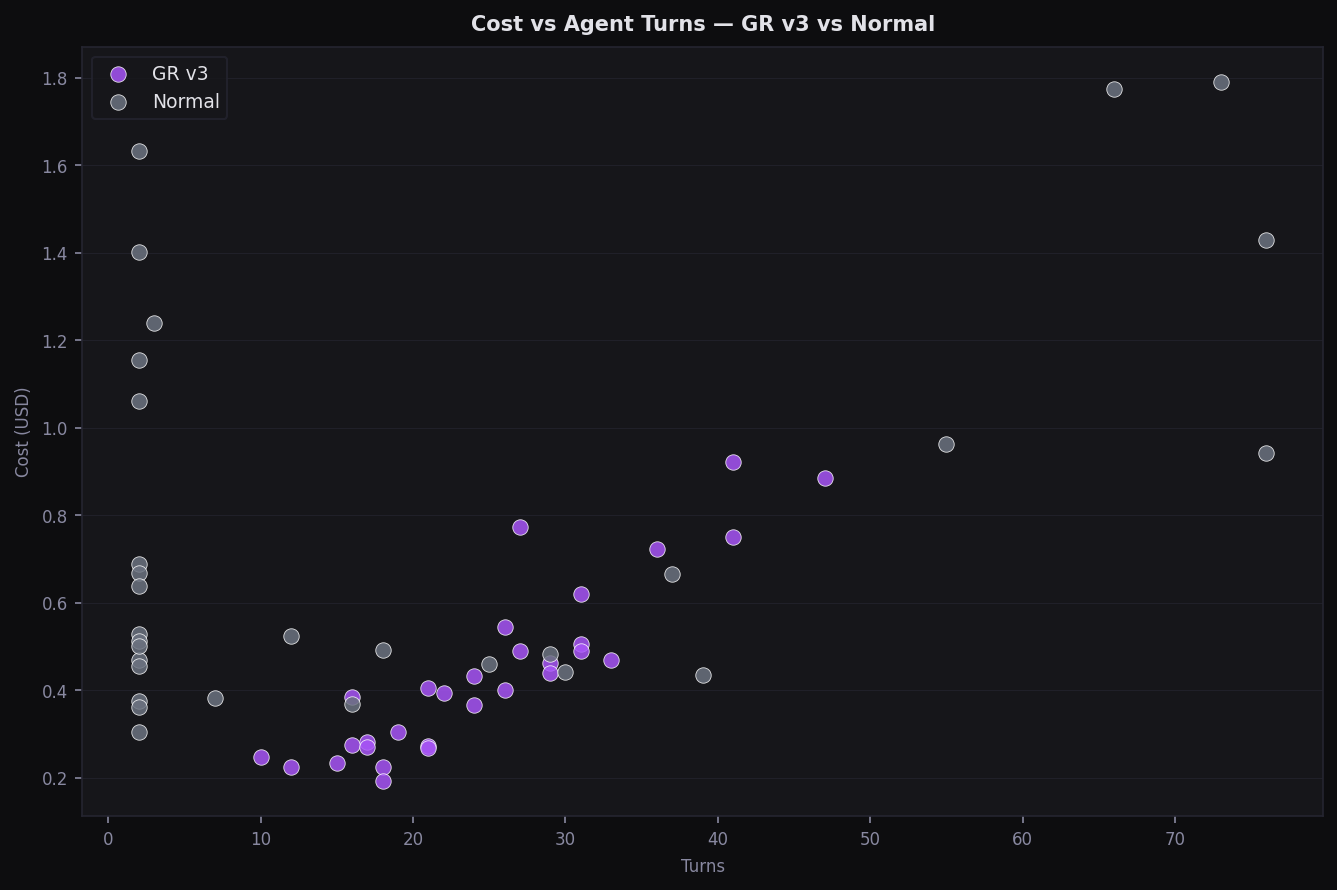
Cost vs Agent Turns
Turn count vs cost — Normal has high variance; GR stays predictable
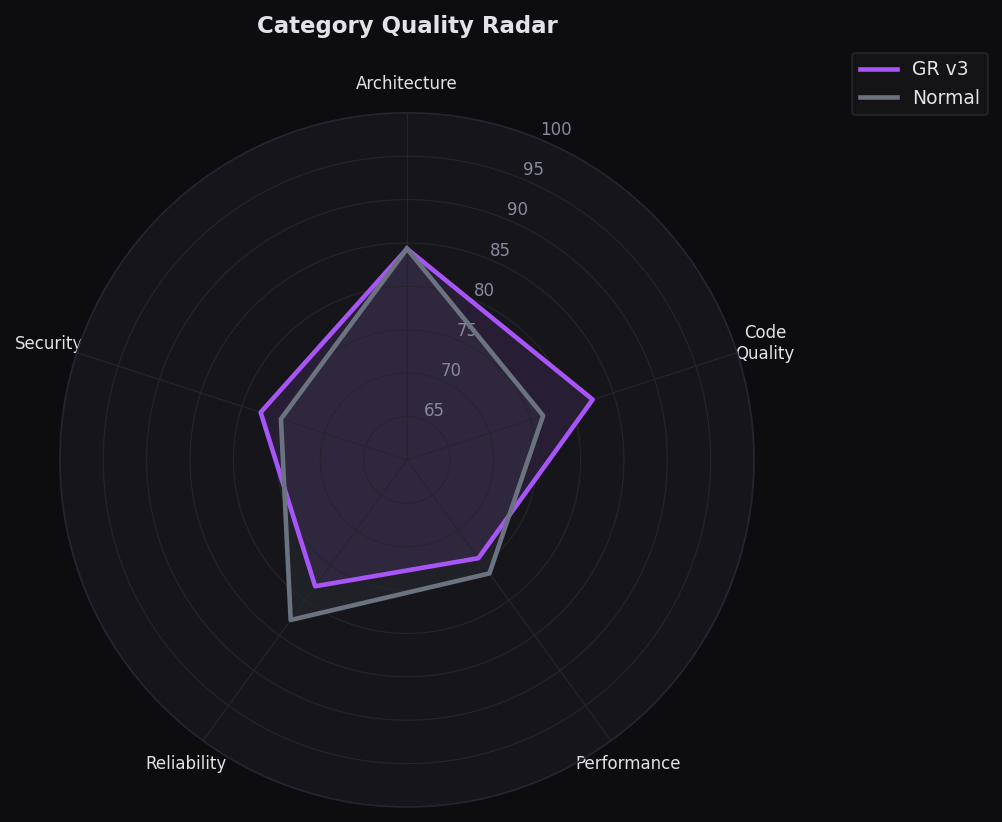
Category Quality Radar
Polar chart across 5 categories — GR v3 leads on architecture, security
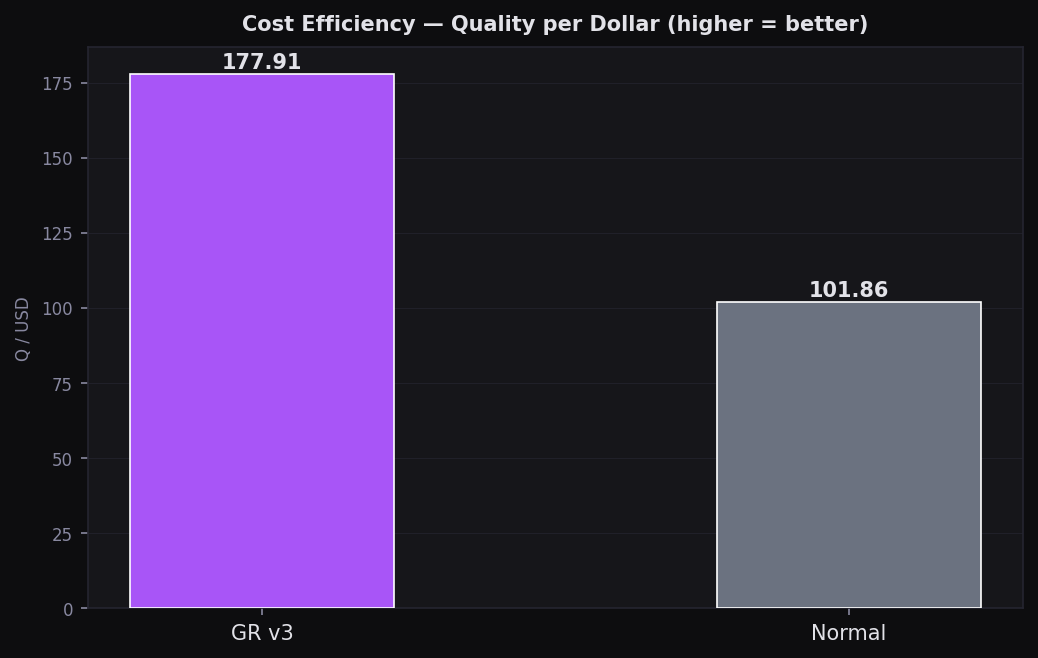
Cost Efficiency (Q/$)
Quality per dollar — GR v3 at 1.78 Q/$ vs Normal at 1.02 Q/$
Community Challenge — Beat GR v3
GR v3 scored 78.4/100 avg quality at $13.25 total on getsentry/sentry (~7,762 Python files). Run the same 30 prompts with your own setup — any tool, any MCP, any CLAUDE.md — and submit. Beat us on quality, cost, or both.
Methodology
# 2 isolated copies of getsentry/sentry (~7,762 Python files)
# Each mode runs every prompt independently, no shared state
MODES = {
"gr-v3": {
"mcp": "graperoot-v3",
"model": "claude-sonnet-4-6", # single agent, no subagents
},
"normal": {
"mcp": None, # bash + grep tools only
"model": "claude-sonnet-4-6", # main agent (Sonnet 4.6)
# ↳ spawns claude-haiku-4-5 subagents for search operations
# those API calls are counted in the total cost
},
}
# All $ figures = Anthropic API charges (input + output + cache tokens)
# Cost difference is real: Normal spawns 3–8 Haiku subagents per prompt
# Scoring: 5-dimension LLM judge (Claude Sonnet 4.6)
# findings_accuracy /20 · coverage_breadth /19 · depth_quality /15
# fix_completeness /12 · actionability /8 · total /74 (mapped 0-100)
# Prompts 1-20: targeted · Prompts 21-30: multi-intent (labelled MI)Benchmark run March 2026 · getsentry/sentry (~7,762 Python files) · 30 prompts · GR v3: Claude Sonnet 4.6 only · Normal: Sonnet 4.6 main + Haiku 4.5 subagents (all API costs included) · LLM judge: Claude Sonnet 4.6 · prompts + challenge at github.com/kunal12203/graperoot-benchmark-challenge.