Benchmarks
Does it actually work? We ran the numbers.
5 benchmark runs · 80+ prompts · real 92-file production codebase · same model (Claude Sonnet 4.6), same questions — with and without GrapeRoot.
45%cheaper on complex tasksv3.8.35 challenge benchmark · 10/10 prompts
10/10cost + quality winsclean sweep across challenge benchmark
34%avg savings, E2E benchmark16/20 cost wins · real-world multi-step prompts
Per-Prompt Cost
Cost per prompt comparison
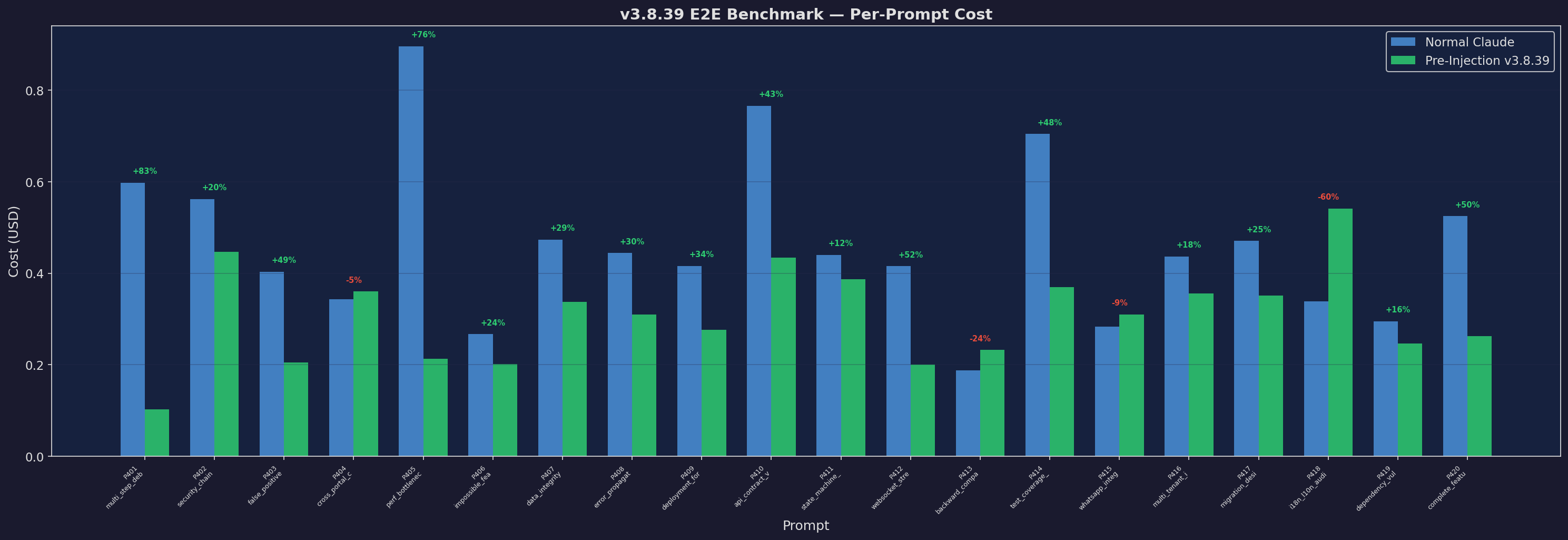
Expand
Quality (Regex + LLM)
Dual-scored quality
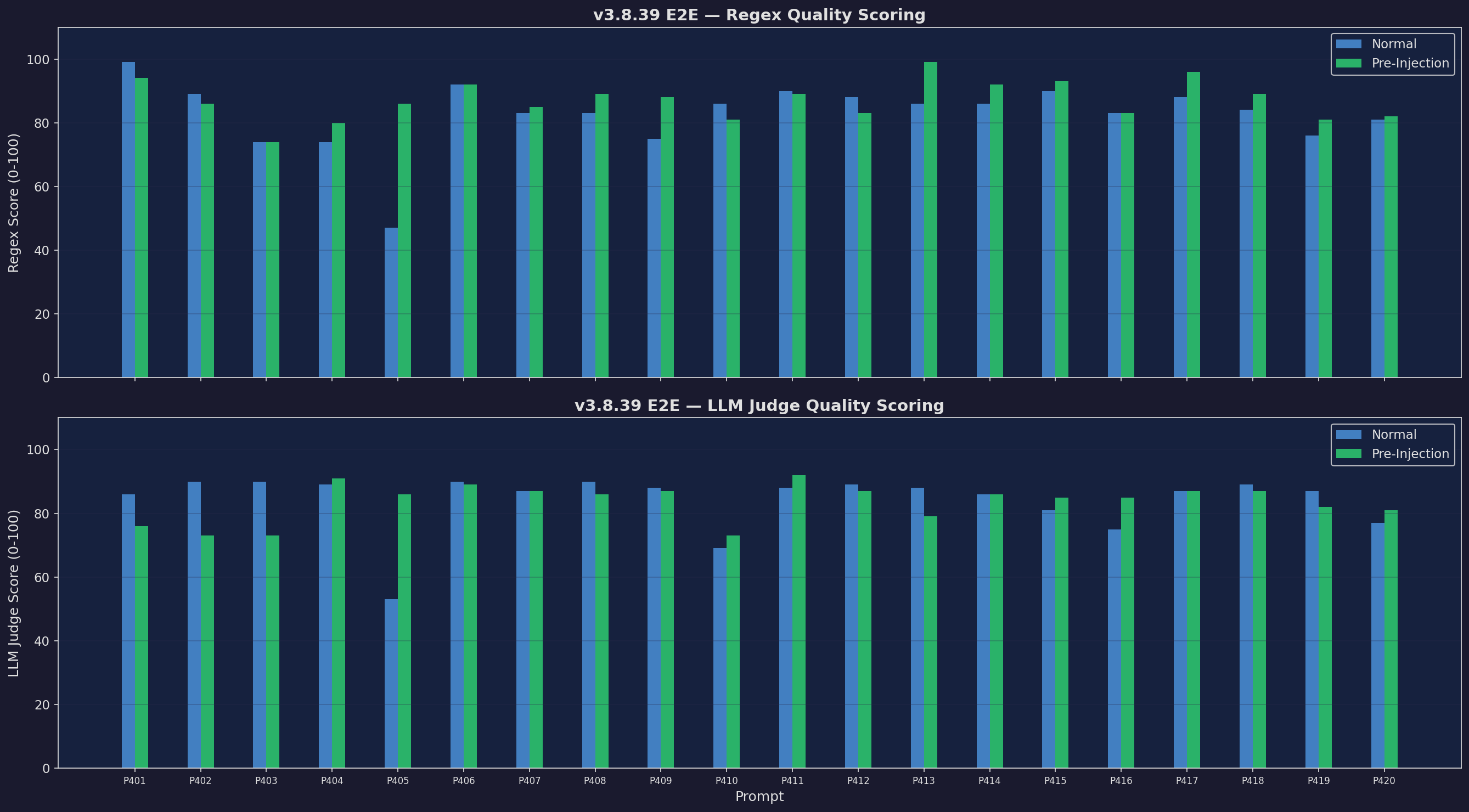
Expand
Turns & Wall Time
Fewer turns, faster responses
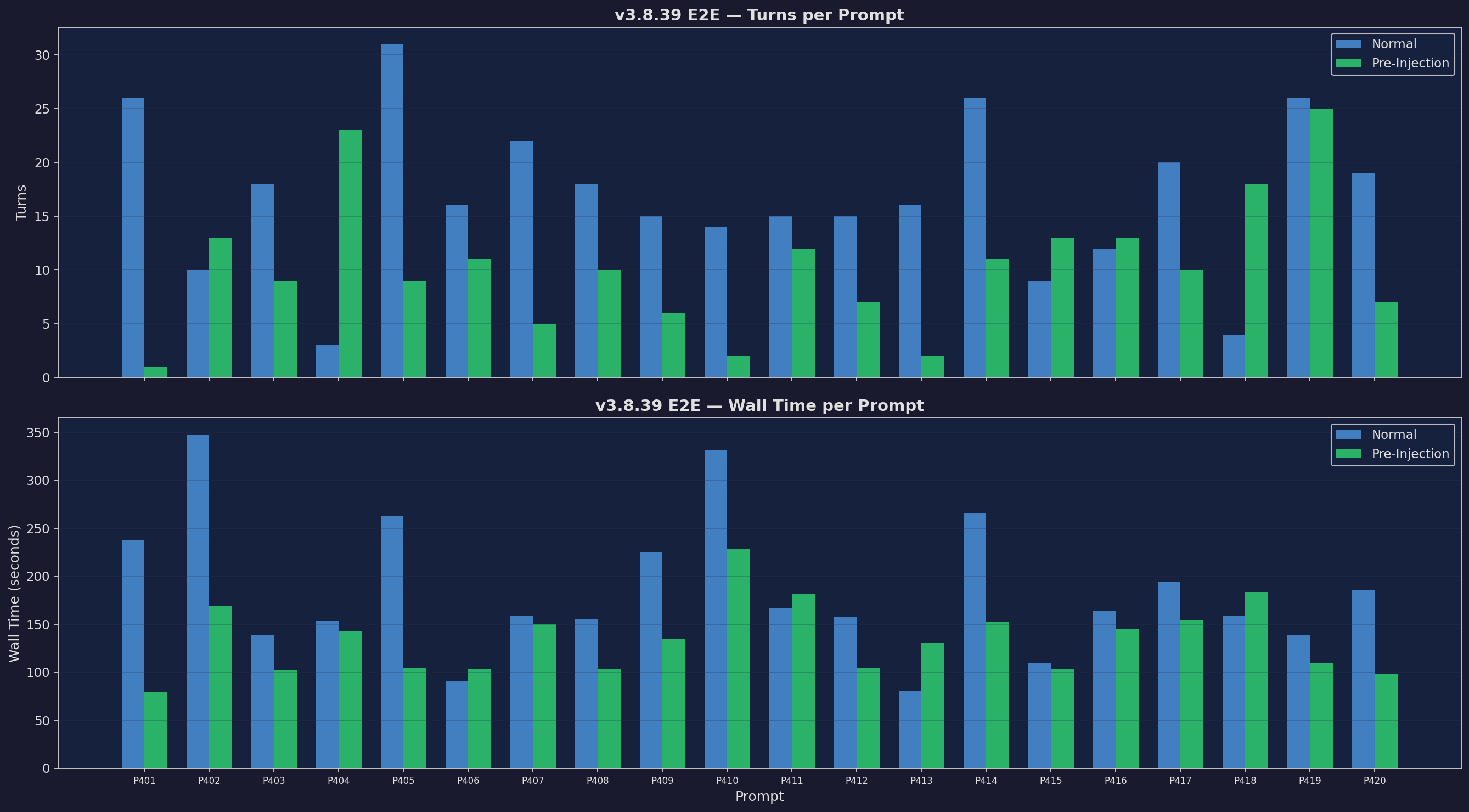
Expand
Savings Waterfall
Per-prompt cost savings
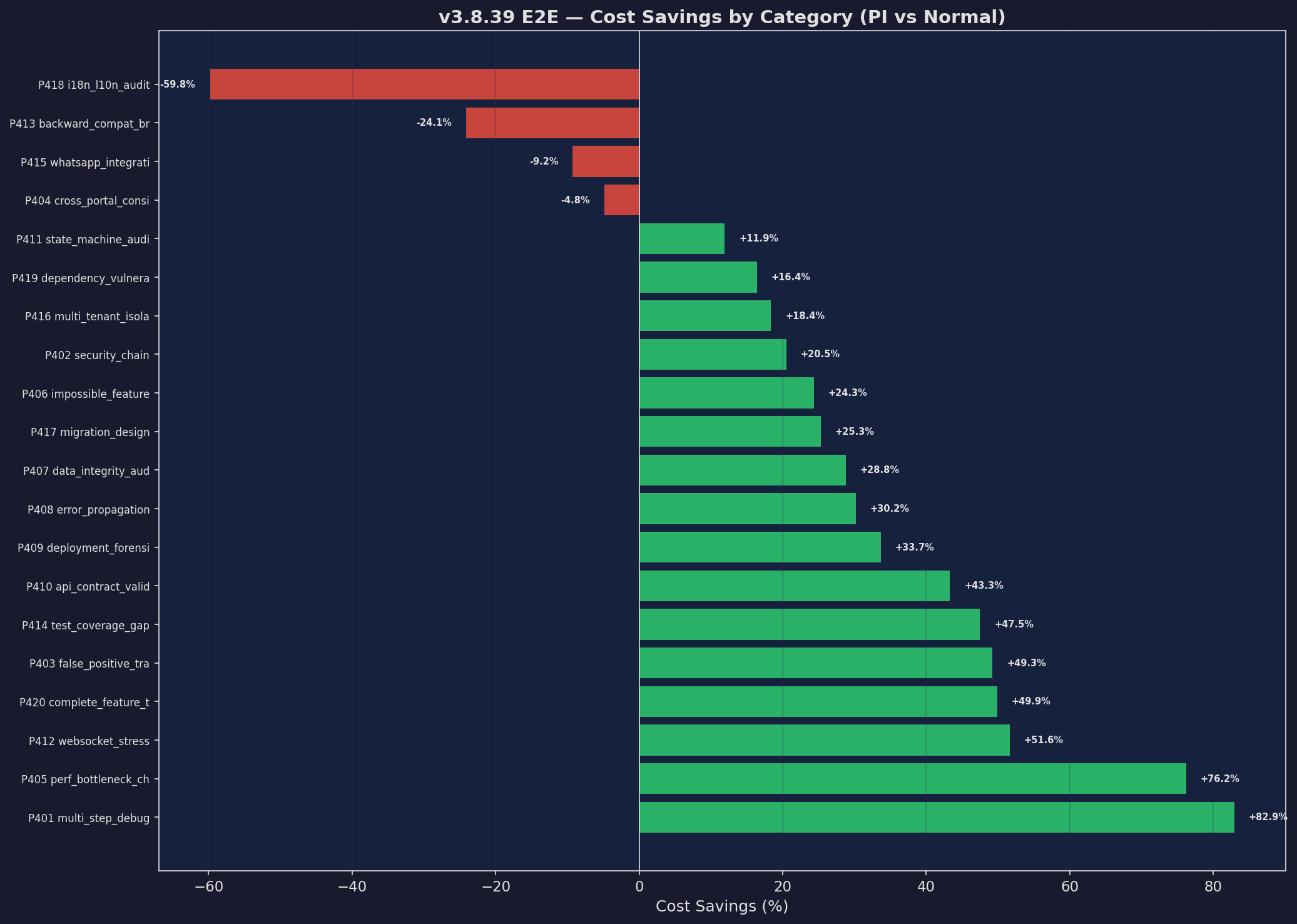
Expand
Quality Radar
Multi-axis quality comparison
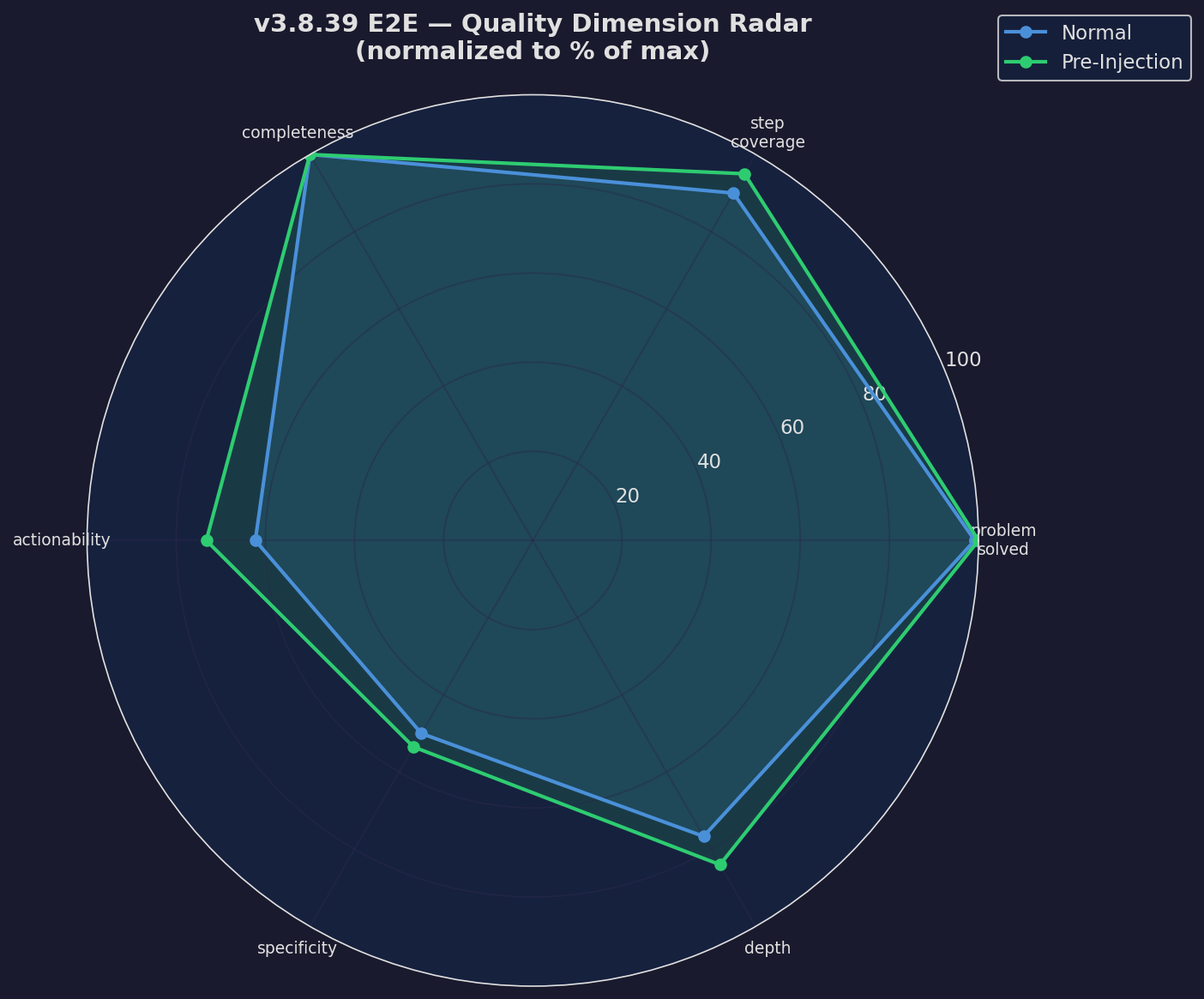
Expand
Cost vs Quality
Every prompt: cost vs quality scatter
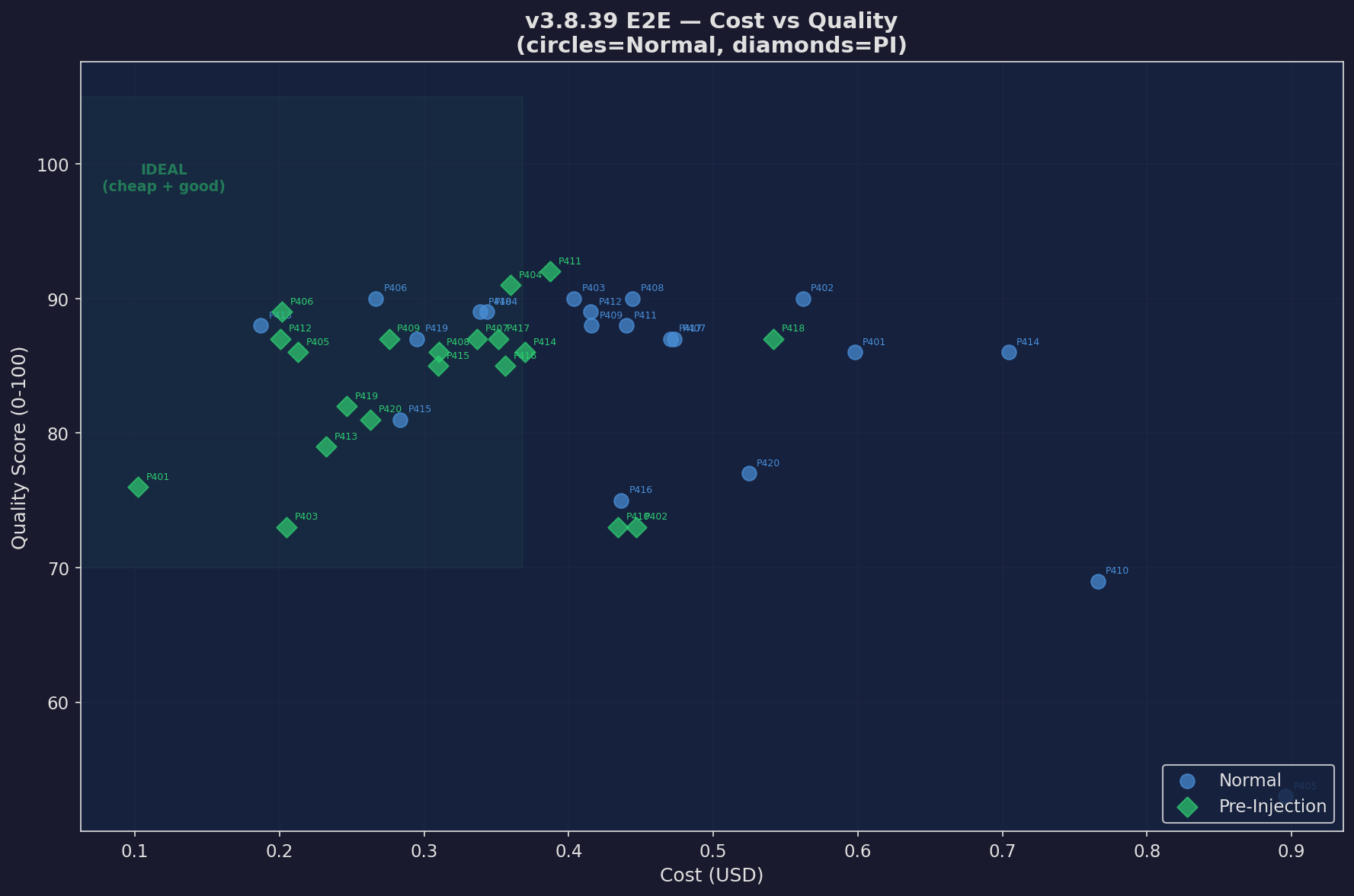
Expand
Classifier Decisions
How the classifier routed prompts
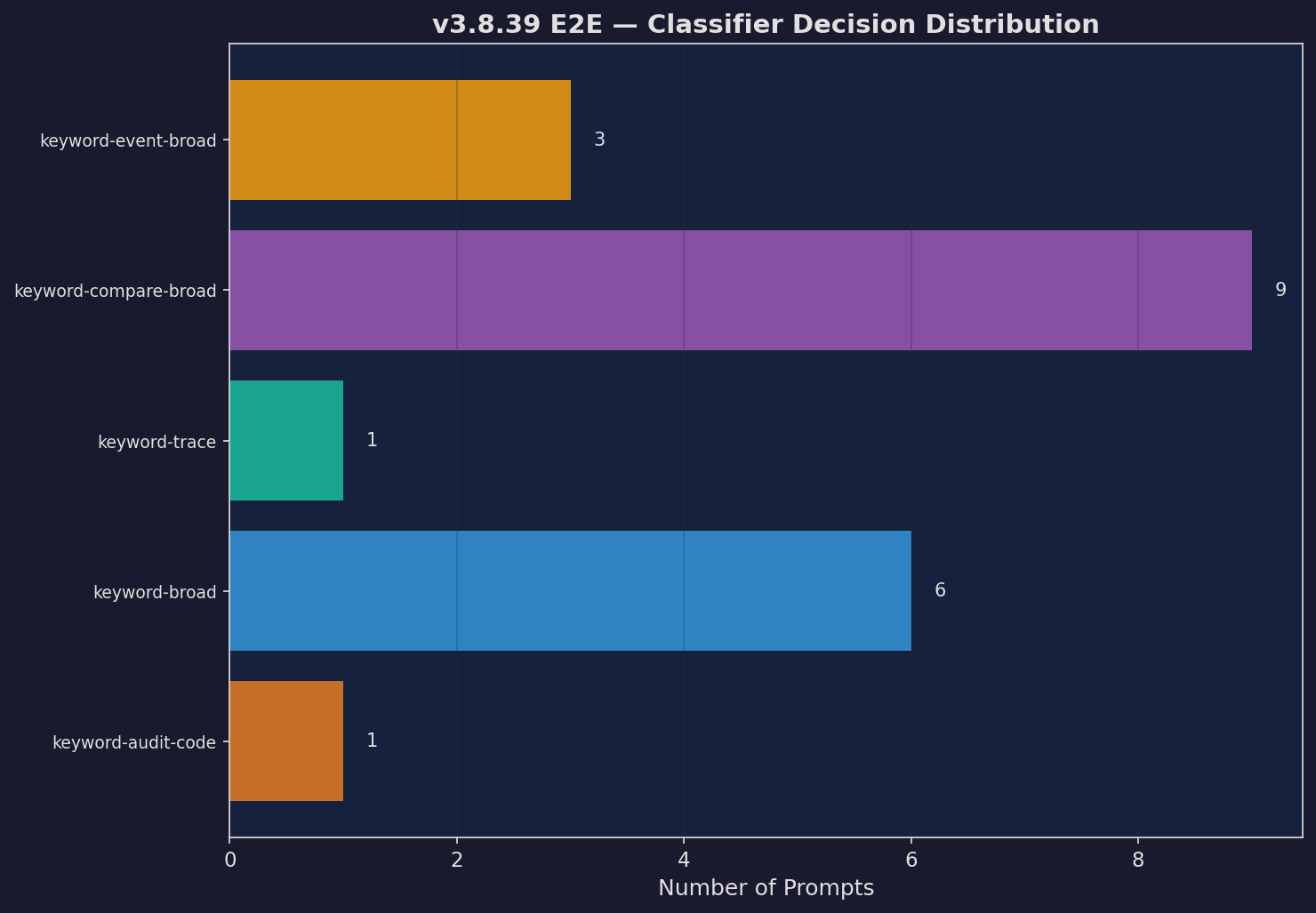
Expand
Bias Analysis
Expected vs actual winners
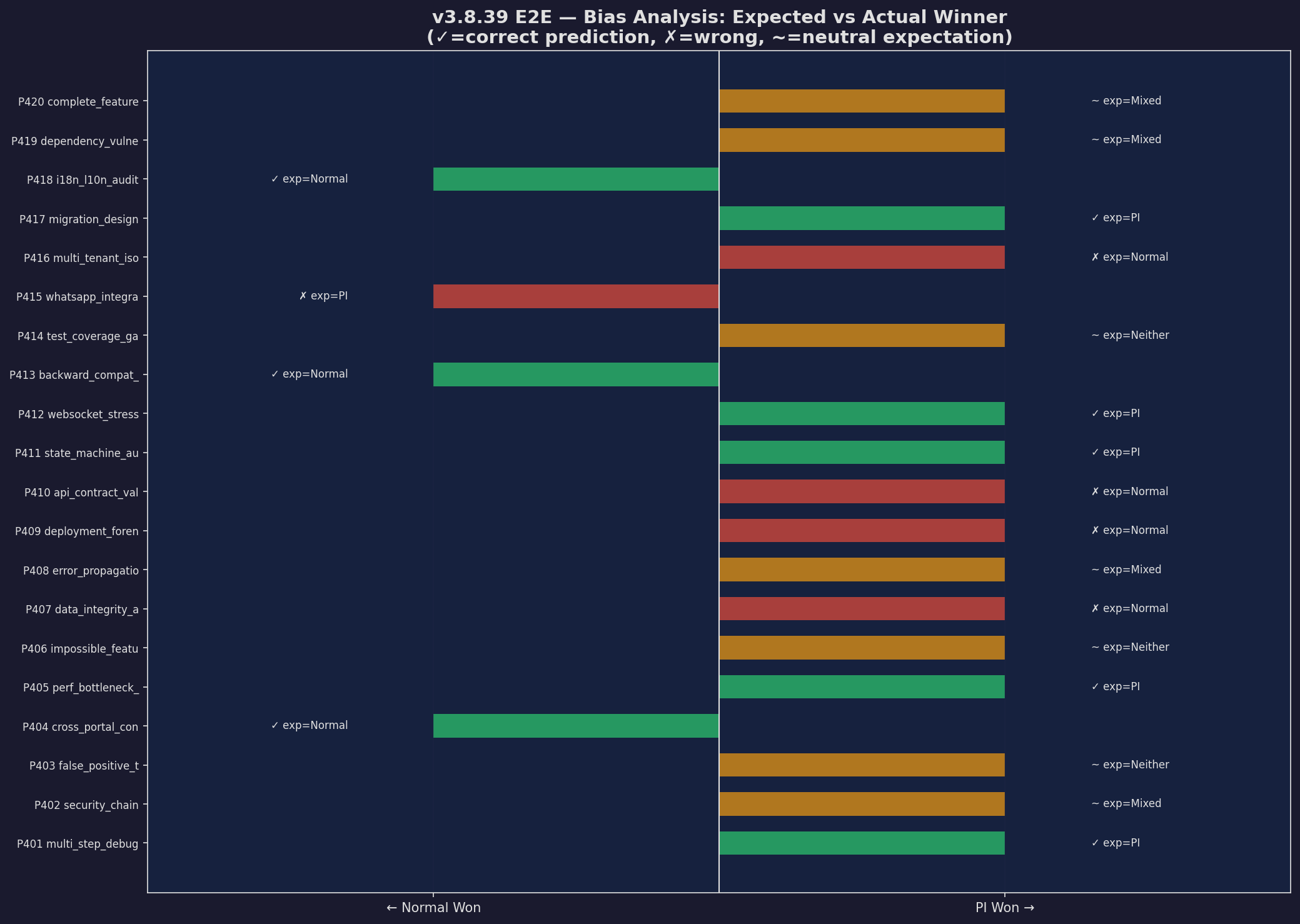
Expand
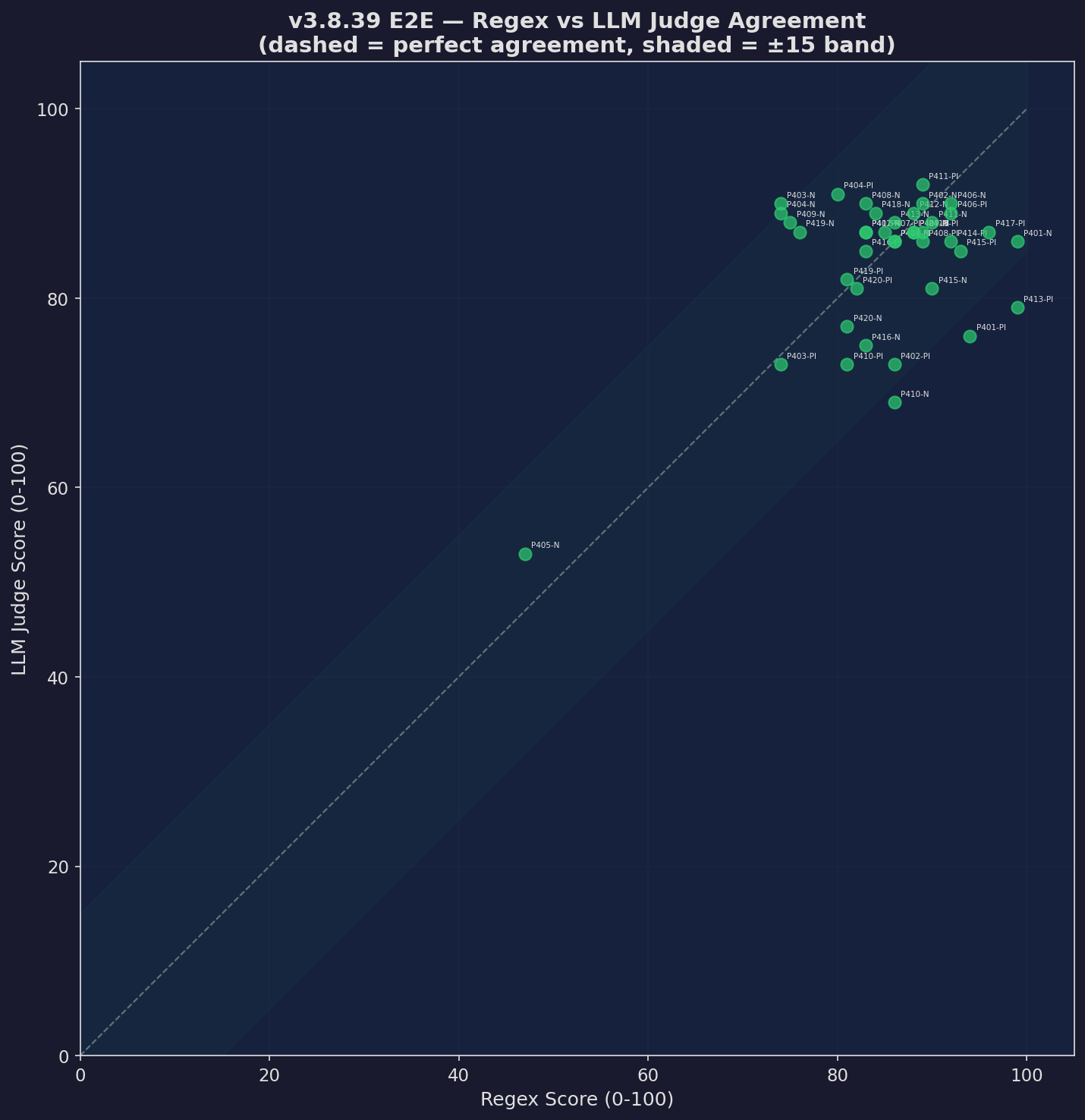
Scorer Agreement
Regex vs LLM judge agreement rate
Expand
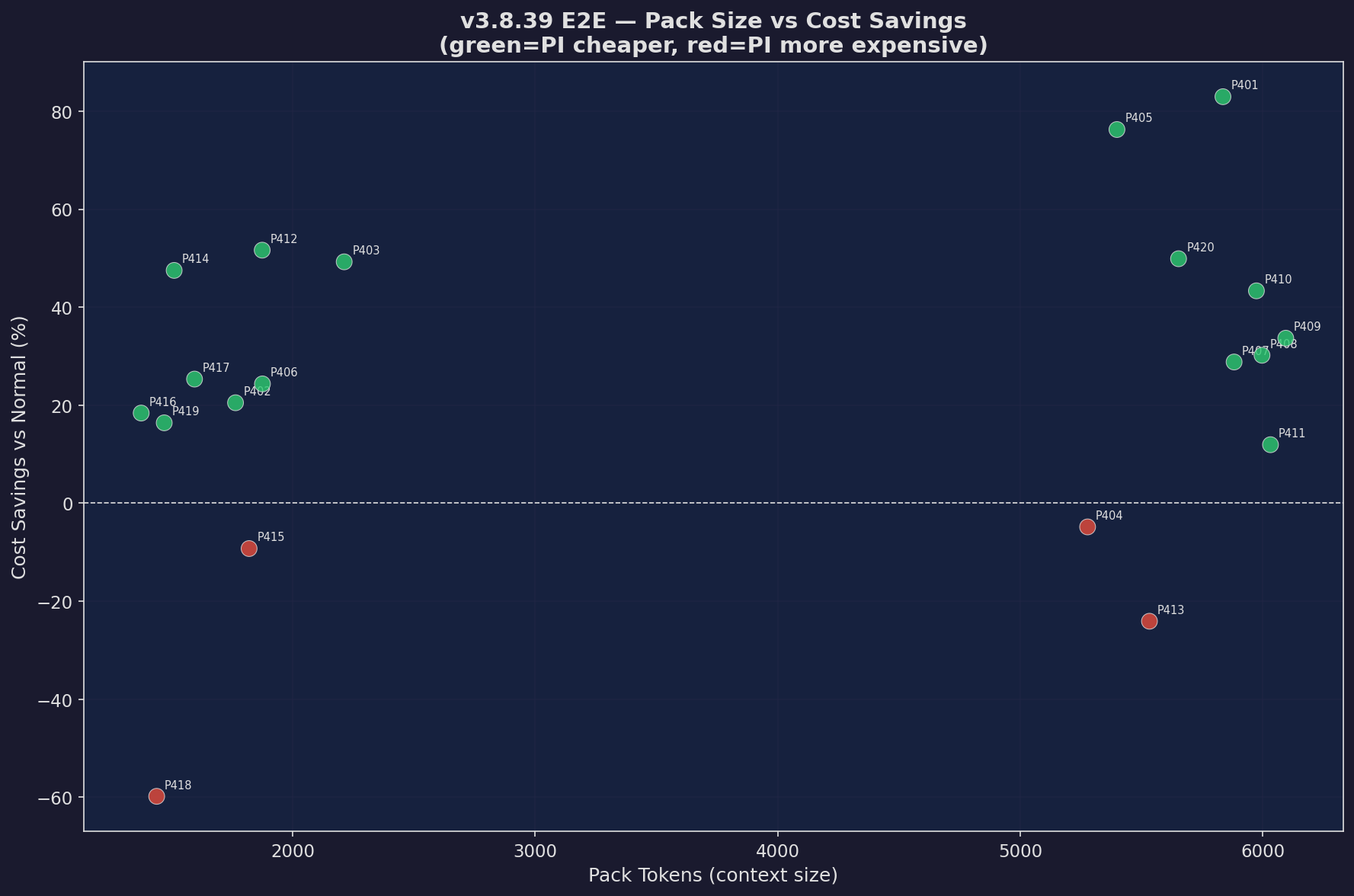
Pack Size vs Savings
Context pack size correlation with savings
Expand