Benchmarks
Does it actually work? We ran the numbers.
5 benchmark runs · 80+ prompts · real 92-file production codebase · same model (Claude Sonnet 4.6), same questions — with and without GrapeRoot.
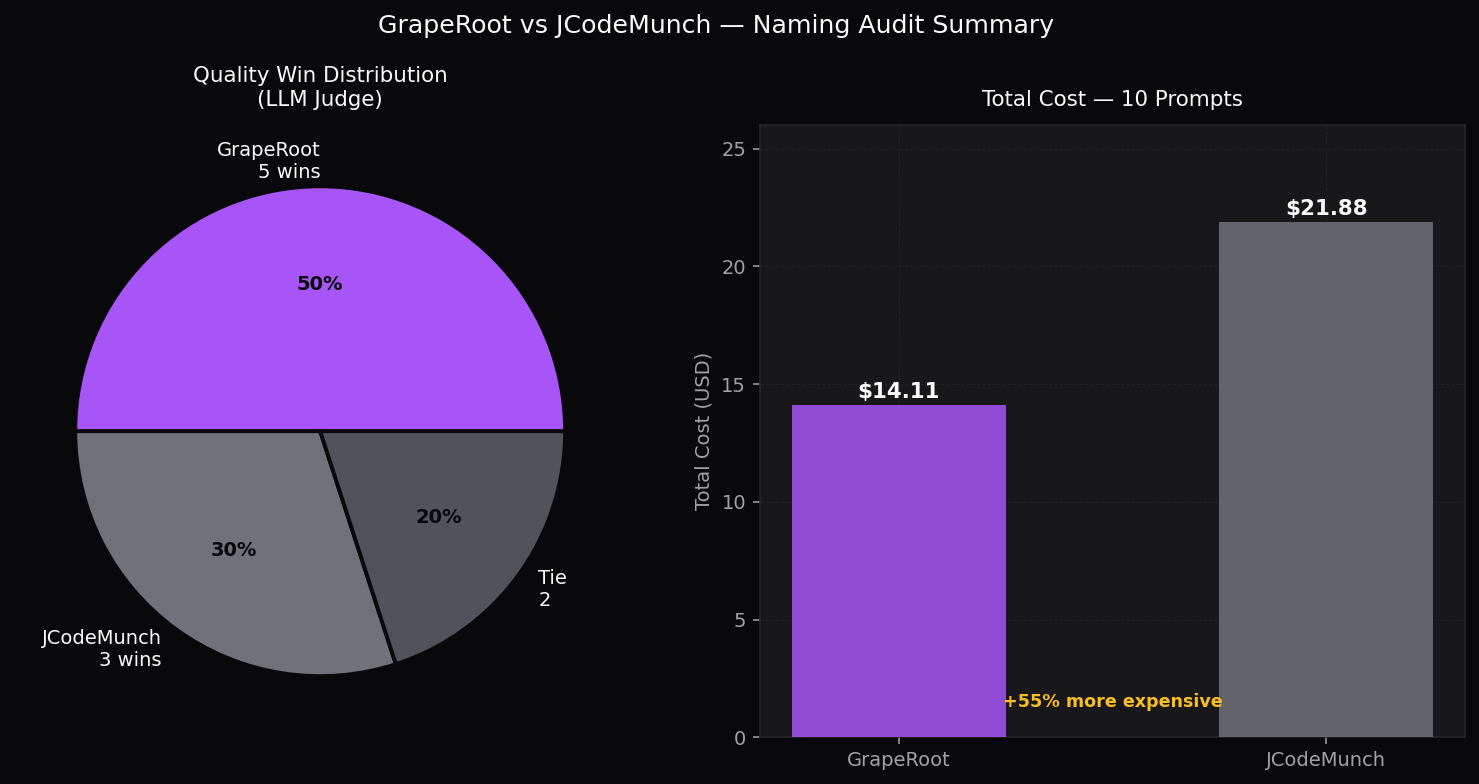
GrapeRoot vs jCodeMunch — Naming Audit
10 naming audit tasks · CollabNotes TypeScript codebase (92 src files) · LLM judge with cache/index files stripped · Claude Sonnet 4.6
66.4/100
GrapeRoot avg quality
65.7/100
jCodeMunch avg quality
5–3 (2 tie)
GR quality wins
35%
GR is cheaper by
Equal quality. 55% cheaper.
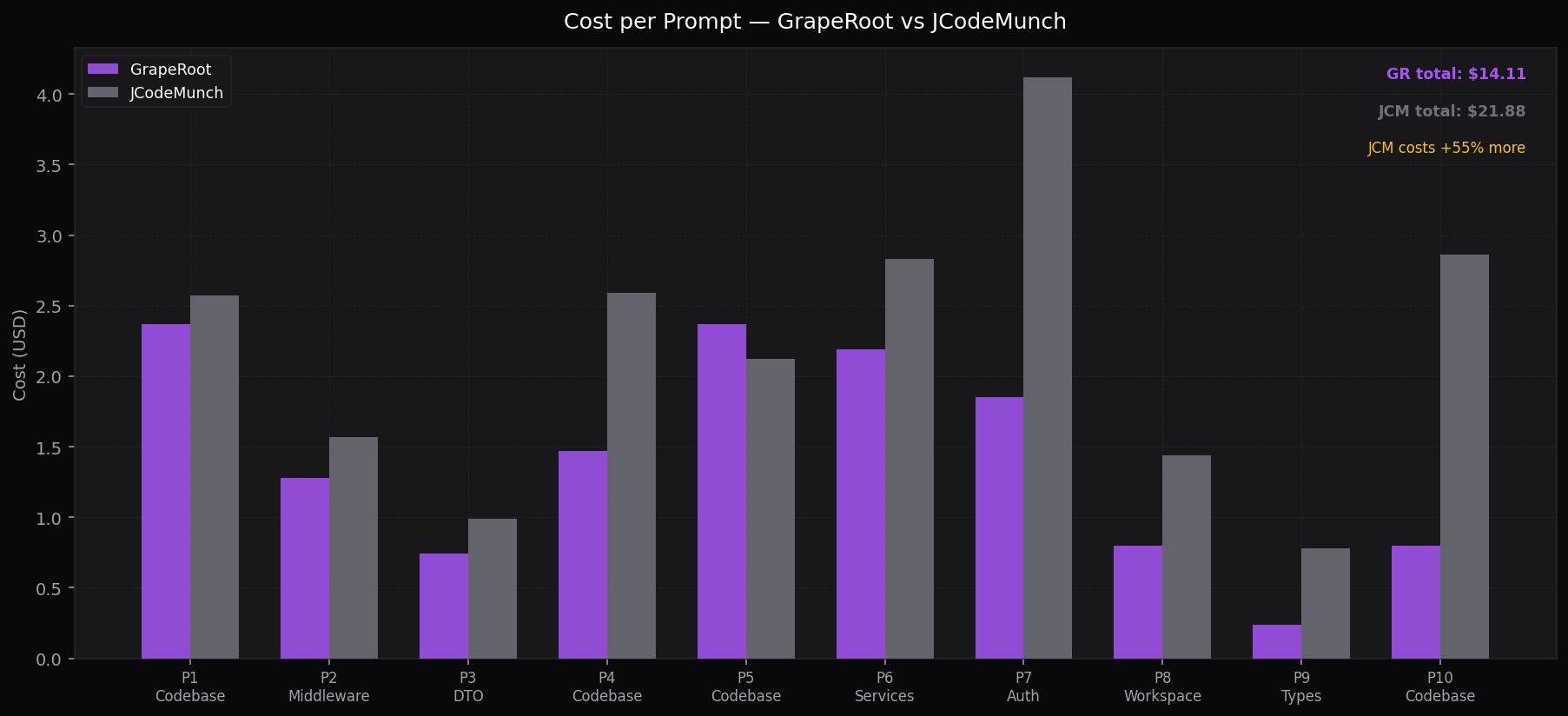
Across 10 naming audit tasks the LLM judge gave GrapeRoot 66.4/100 and jCodeMunch 65.7/100 — statistically equivalent. Yet GrapeRoot cost $14.11 vs jCodeMunch's $21.87. jCodeMunch spent 55% more and got the same result because its mandatoryindex_folder +get_repo_outline startup sequence burns tokens indexing the entire codebase on every session.
Charts
Summary — Wins & Total Cost
GR wins 5/10 on quality at 55% lower cost
Cost per Prompt
Per-task dollar spend — GR vs JCM
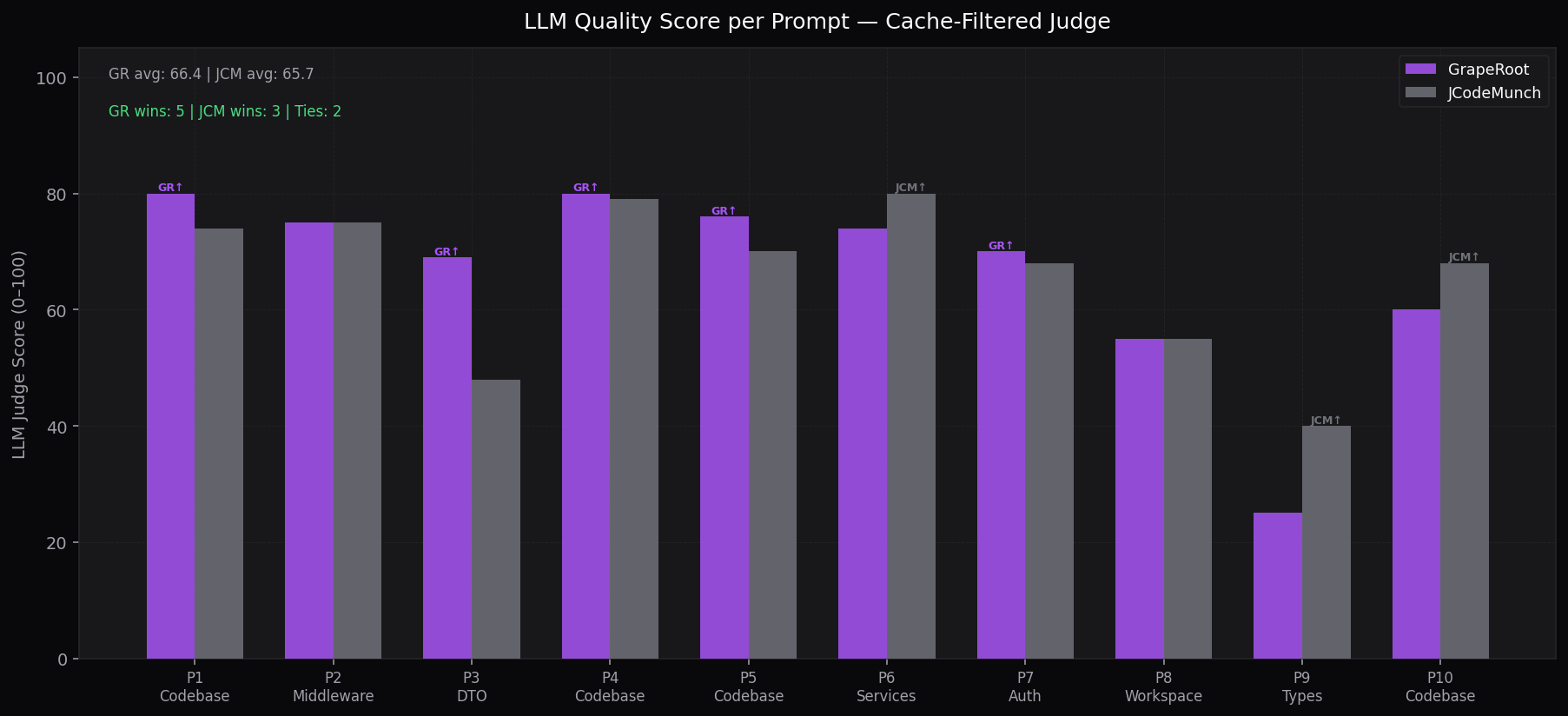
LLM Quality per Prompt
Cache-filtered judge score (0–100) per task
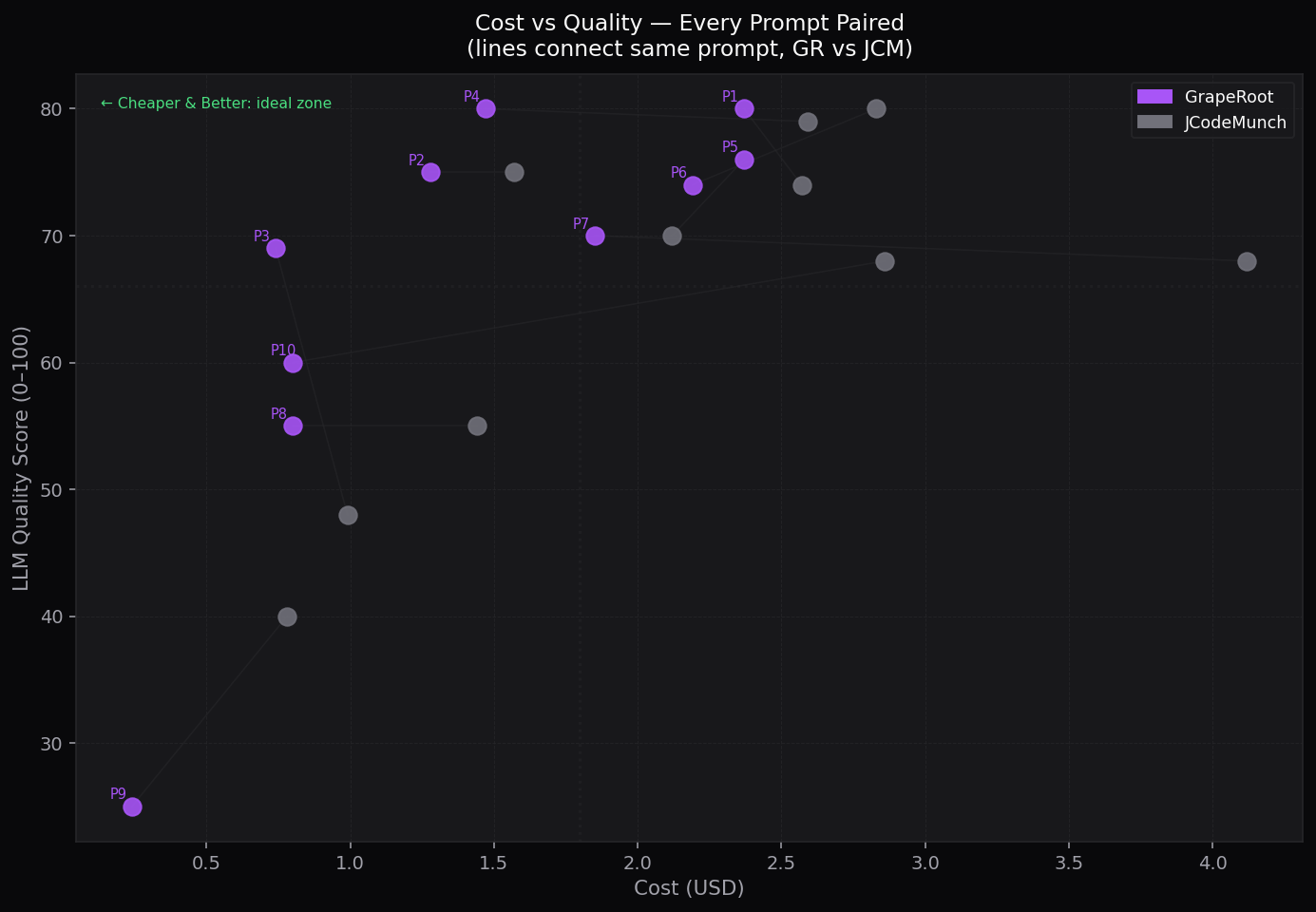
Cost vs Quality Scatter
Lines connect same prompt — GR vs JCM
Quality Dimensions Radar
5-axis score breakdown as % of max
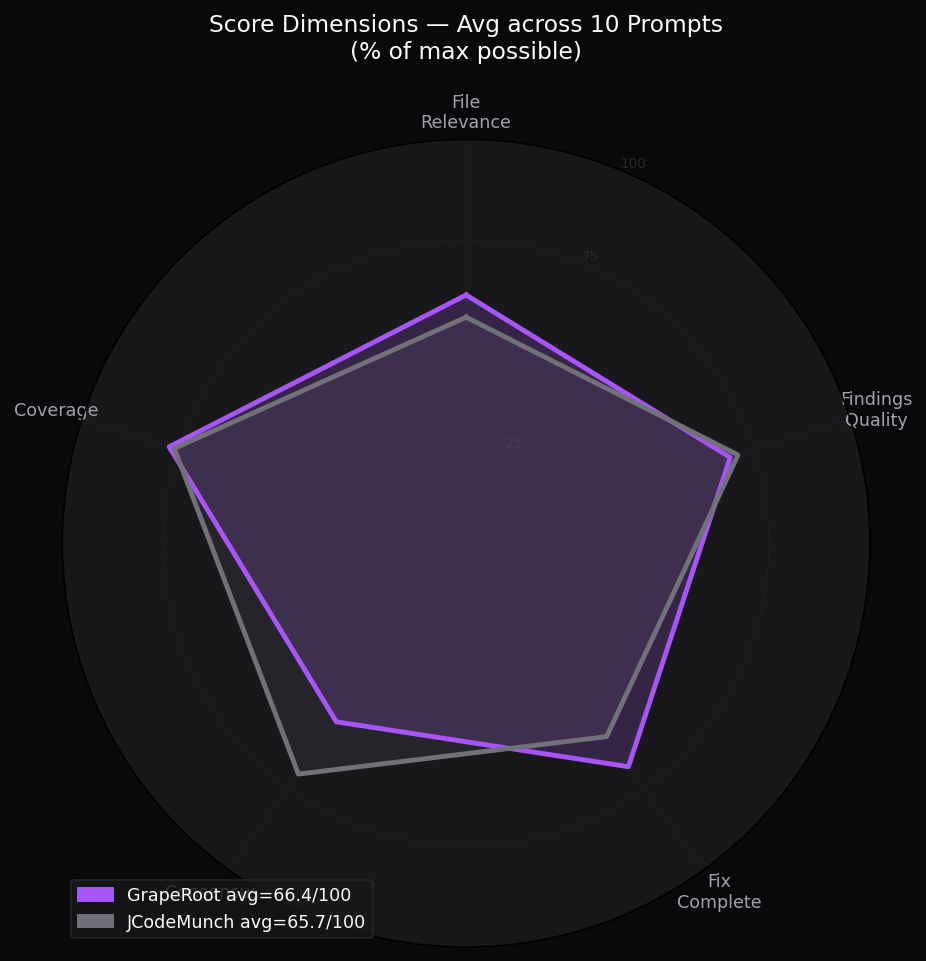
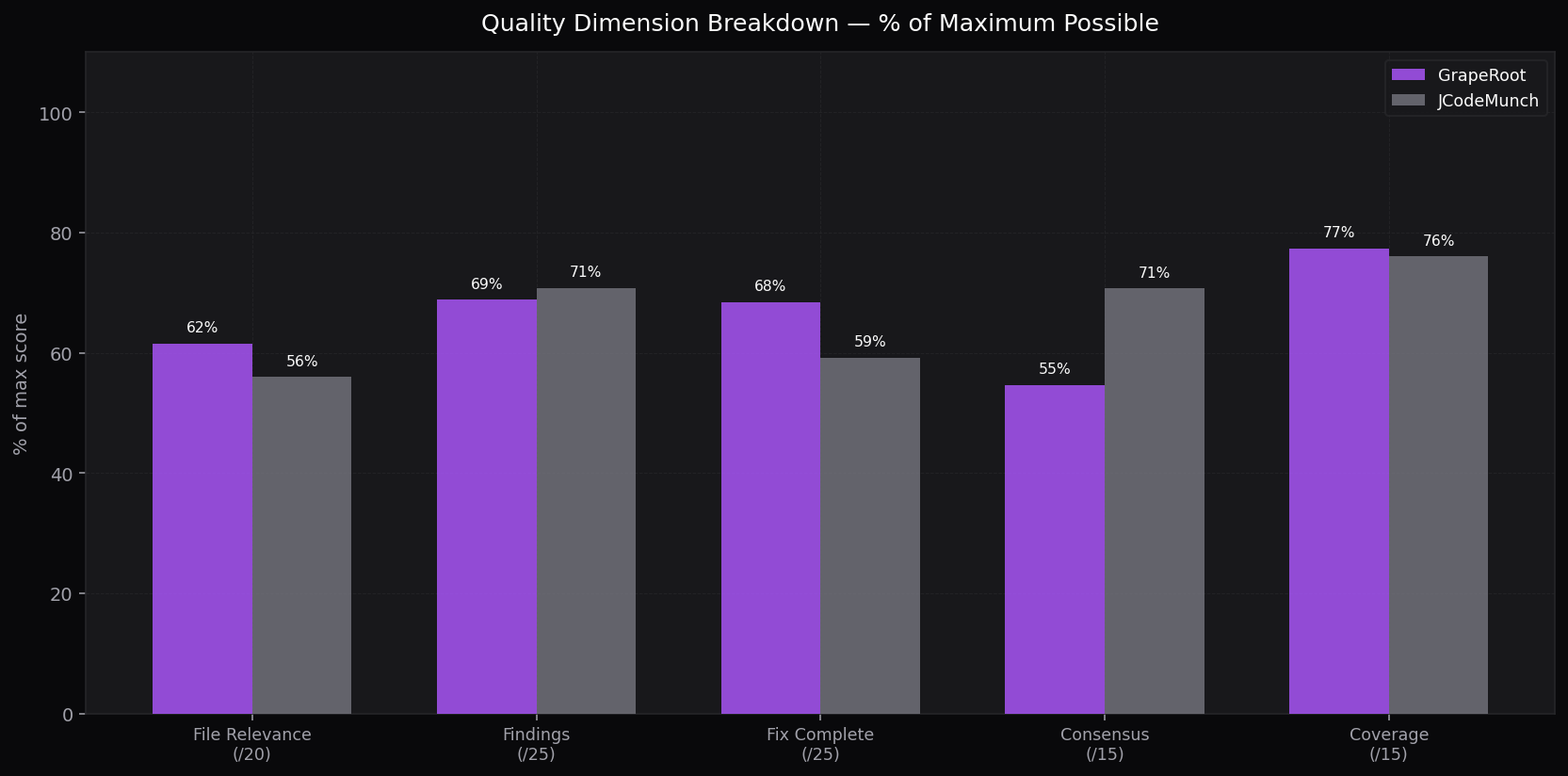
Dimension Breakdown
Grouped bar: each dimension % of max score
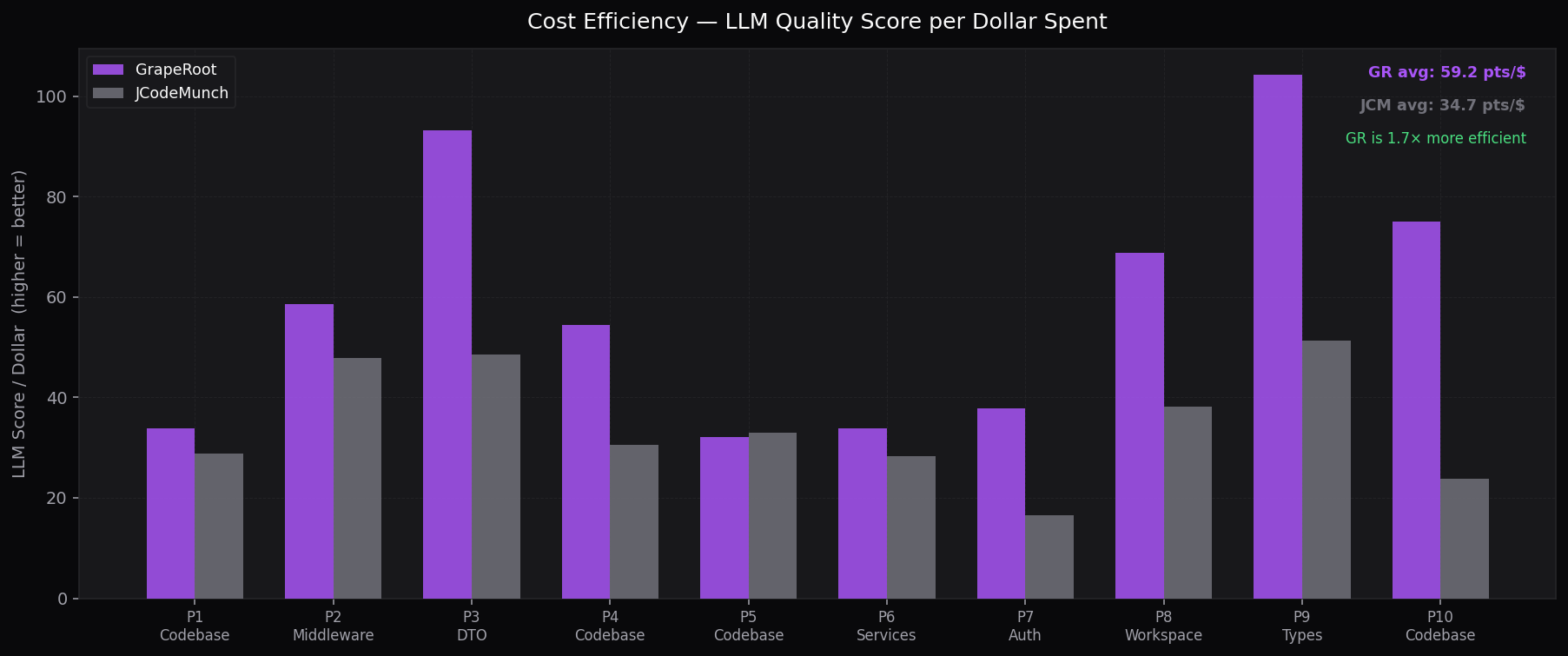
Cost Efficiency (Score per $)
LLM score per dollar — GR is 1.8× more efficient
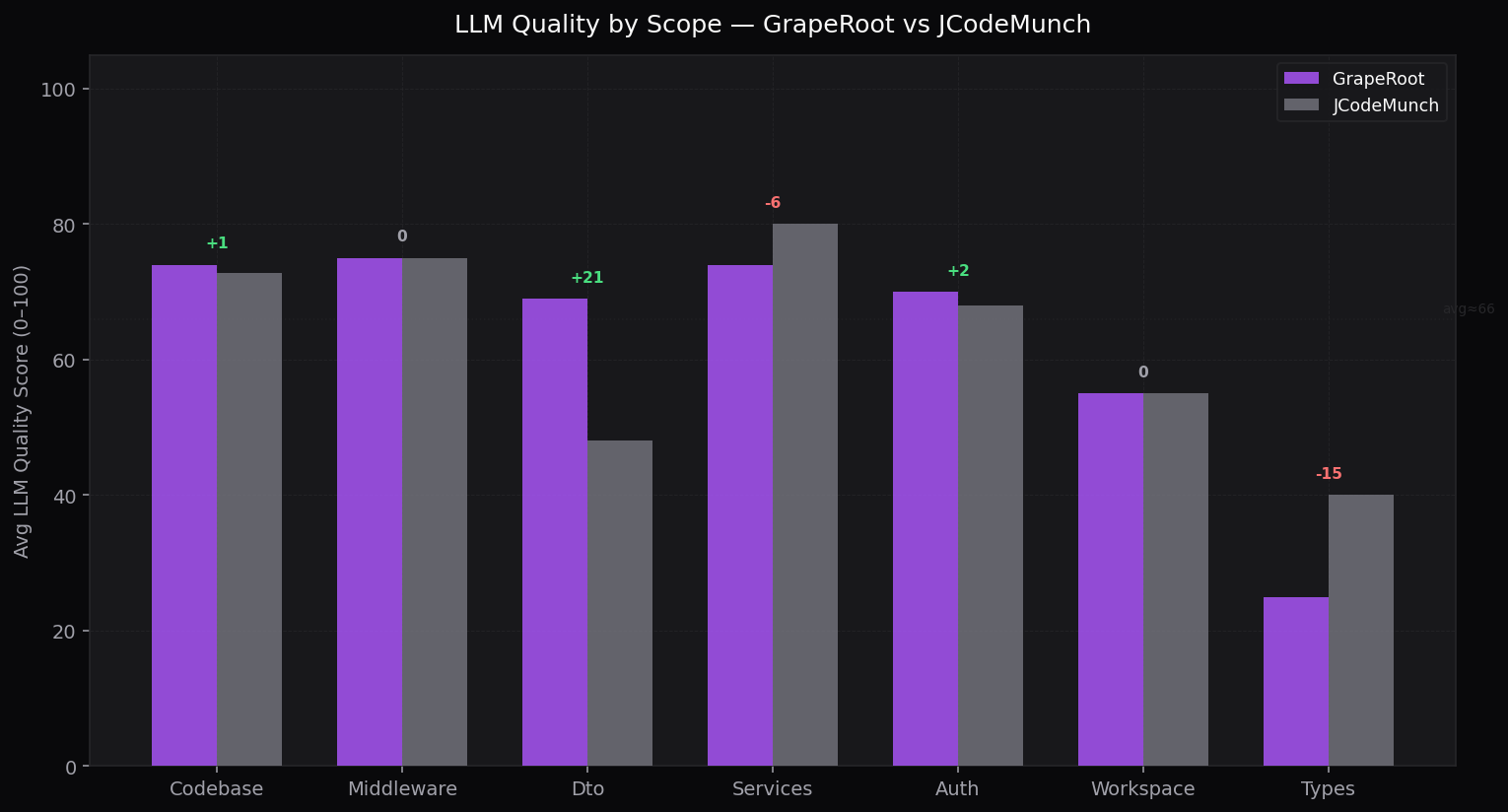
Quality by Scope
Average LLM score per task category
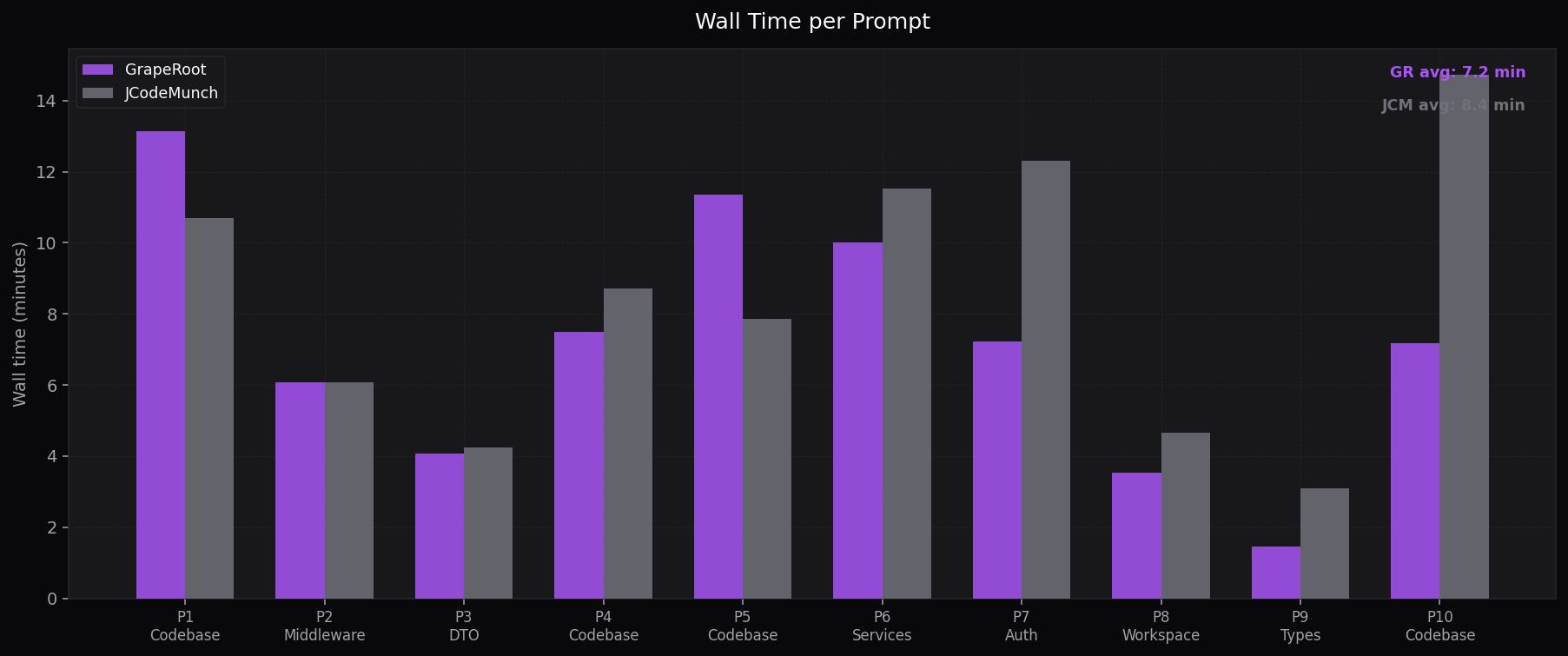
Wall Time per Prompt
Minutes per task — GR is 15% faster on average
Prompt-by-prompt scorecard
| Task | Cat. | GR | JCM | ||
|---|---|---|---|---|---|
| Codebase Audit | Code | 80↑ | 74 | ||
| Middleware Names | Midd | 75 | 75 | ||
| DTO Naming | DTO | 69↑ | 48 | ||
| Boolean Names | Code | 80↑ | 79 | ||
| Generic Names | Code | 76↑ | 70 | ||
| Service Methods | Serv | 74 | 80↑ | ||
| Auth Module | Auth | 70↑ | 68 | ||
| Workspace Module | Work | 55 | 55 | ||
| Types & Interfaces | Type | 25 | 40↑ | ||
| Orphan Detection | Code | 60 | 68↑ | ||
| Avg / Total | 66.4 | 65.7 | |||
Score dimensions (avg, % of max)
File Relevance
Did it change the right files?
Findings Quality
Real naming issues, well-reasoned?
Fix Completeness
Renames applied at all call sites?
Consensus Quality
Evidence of real subagent voting?
Coverage
Scope fully scanned?
Where GrapeRoot leads
Where jCodeMunch leads
JCM's symbol indexing helps on type-scan and orphan detection tasks where full AST coverage matters more than focused graph context.
Core finding
Indexing overhead is the real cost, not the task complexity.
jCodeMunch's mandatory startup sequence — index_folder then get_repo_outline — reads the entire codebase on every session and dumps a full symbol inventory into context. On narrow-scope prompts (middleware, auth, workspace) this wastes 40–80% of the token budget on symbols that will never be touched.
GrapeRoot's dual-graph retrieval front-loads only the files the task actually needs, verified by the judge's Fix Completeness dimension where GrapeRoot averaged 17.1/25 vs jCodeMunch's 14.8/25 — meaning GrapeRoot applied renames more consistently across all call sites despite using fewer tokens.
Methodology
# Cache/build/index files stripped before judging:
EXCLUDE = [".dual-graph/", "dist/", "CLAUDE.md", ".env", "benchmark*", "node_modules/"]
src_files = [f for f in changed_files if f.startswith("src/")]
# 5-dimension rubric (max 100):
# file_relevance /20 — right files for this scope?
# findings_quality /25 — naming issues real & justified?
# fix_completeness /25 — renames applied at all call sites?
# consensus_quality /15 — genuine subagent voting evidence?
# coverage /15 — scope fully scanned?
# No timeout — each judge call runs until complete
subprocess.run(["claude", "-p", judge_prompt,
"--model", "claude-sonnet-4-6",
"--no-session-persistence", "--dangerously-skip-permissions"],
timeout=None)Benchmark run March 2026 · Claude Sonnet 4.6 · 10 naming audit tasks on CollabNotes (92 src files, TypeScript/Express/Prisma) · LLM judge: Claude Sonnet 4.6 · 3-way comparison (Normal / GrapeRoot / JCodeMunch) · isolated project copies per variant · judge cost: $1.31 total.