Benchmarks
Does it actually work? We ran the numbers.
5 benchmark runs · 80+ prompts · real 92-file production codebase · same model (Claude Sonnet 4.6), same questions — with and without GrapeRoot.
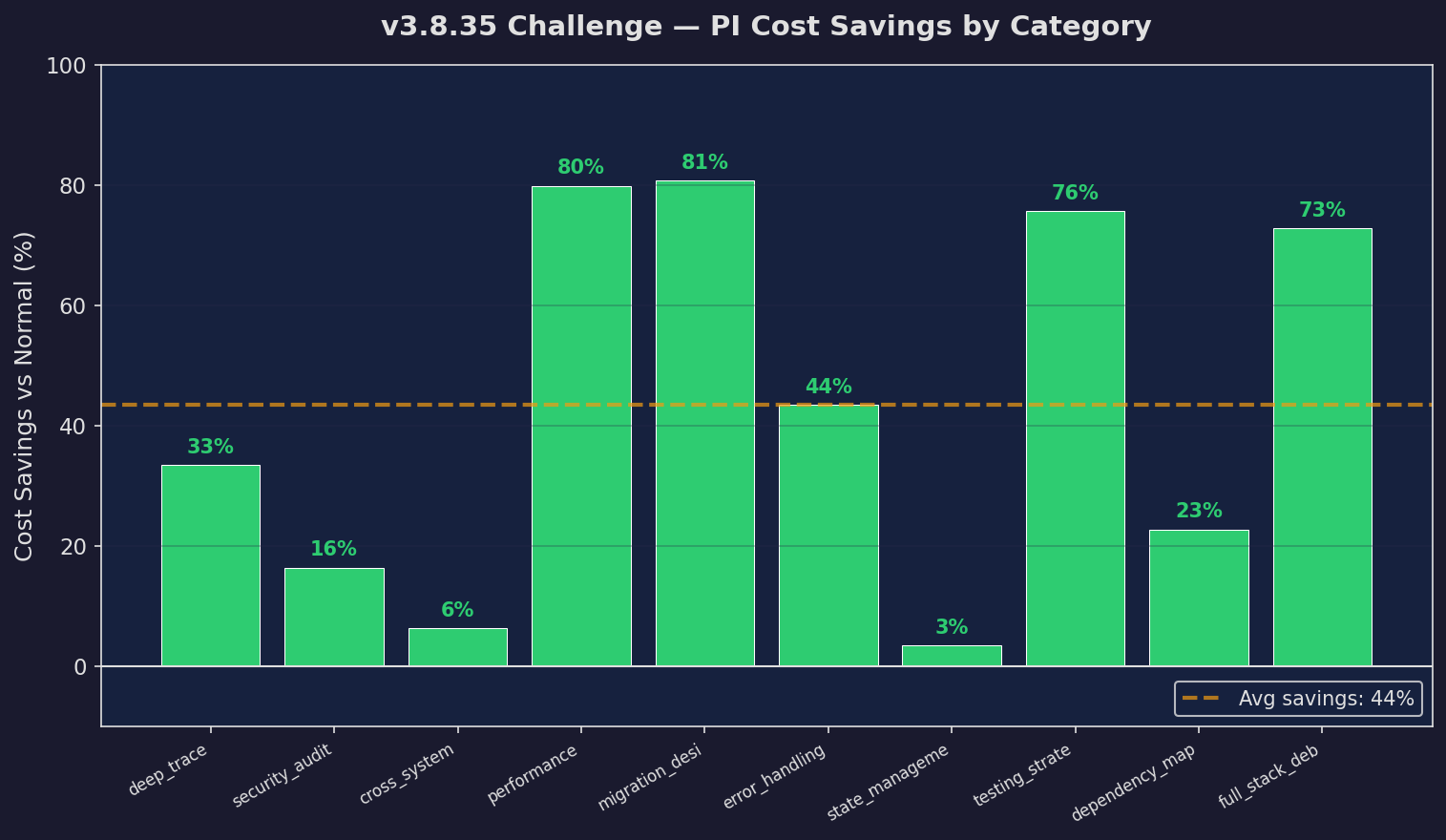
Per-Task Savings (v3.8.35)
Cost reduction per task type — up to 81%
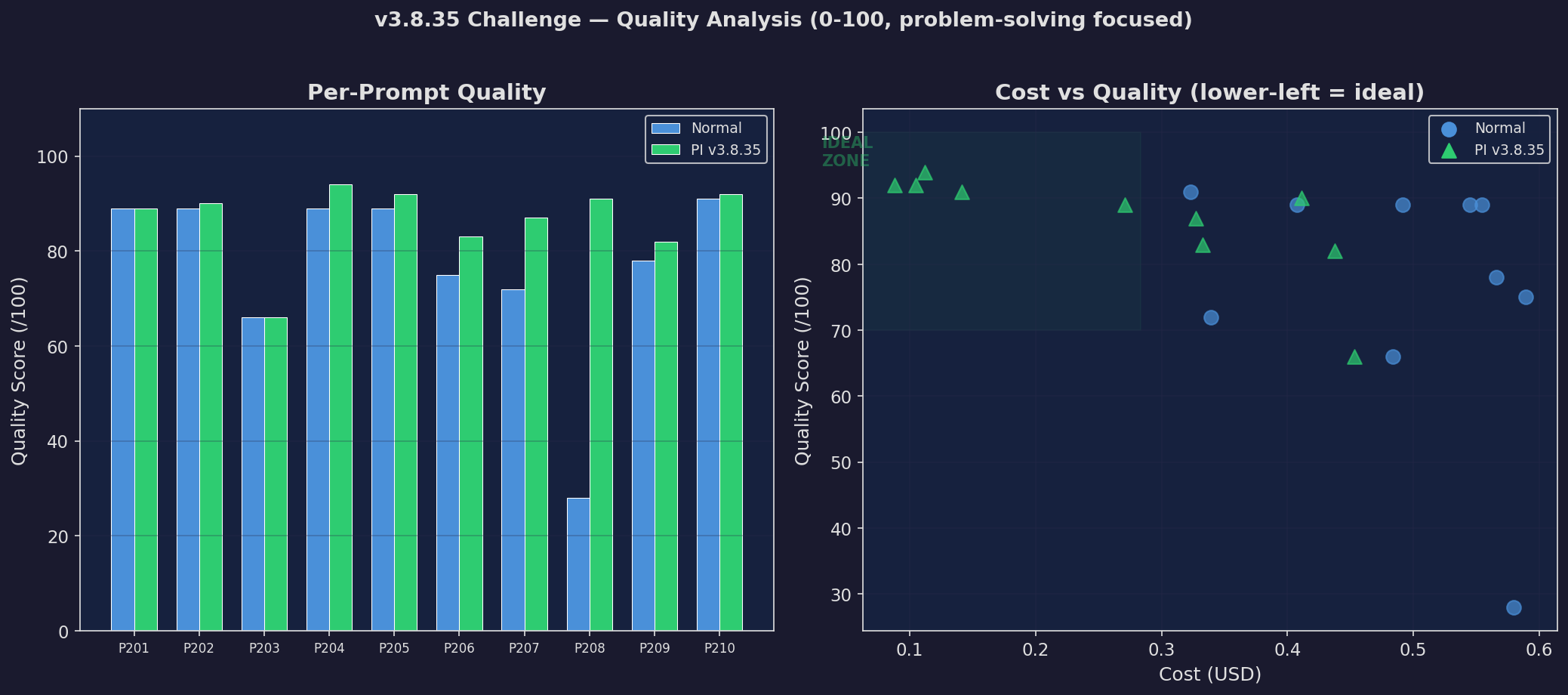
Quality Comparison (v3.8.35)
GrapeRoot vs Normal — quality held or improved on every prompt
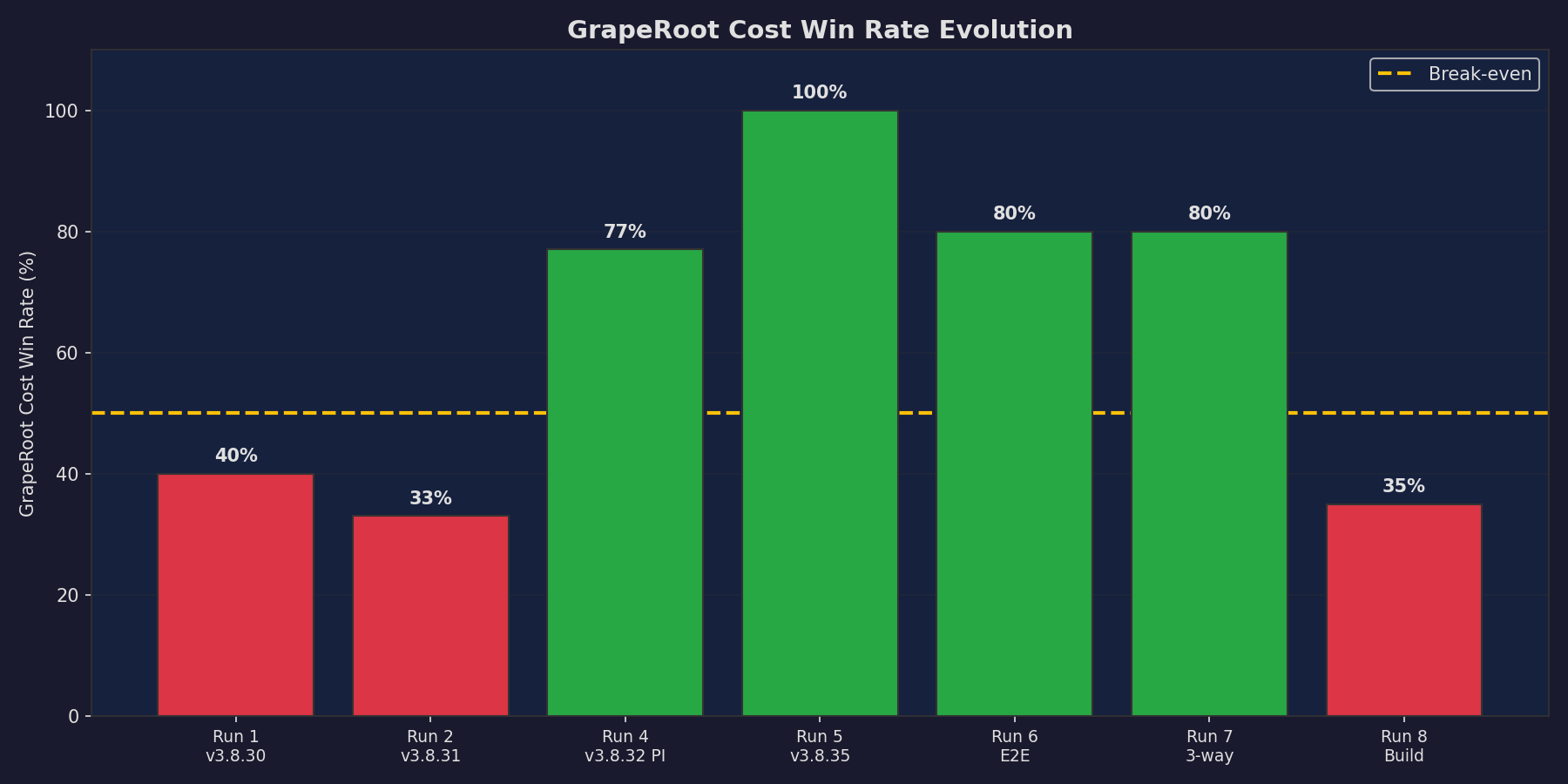
Win Rate Evolution
How GrapeRoot improved across benchmark runs
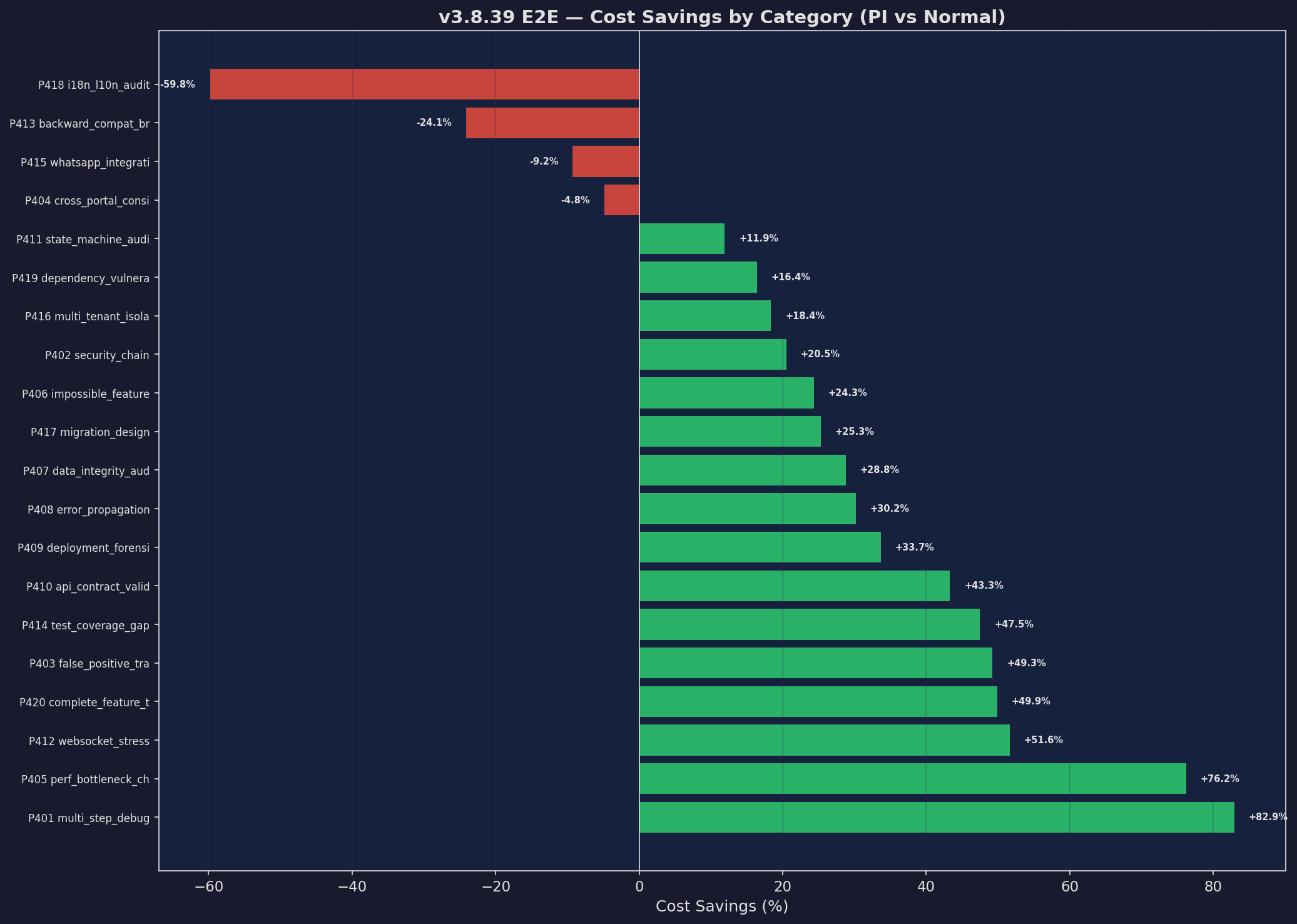
E2E Savings Waterfall
Per-prompt savings across 20 real-world tasks
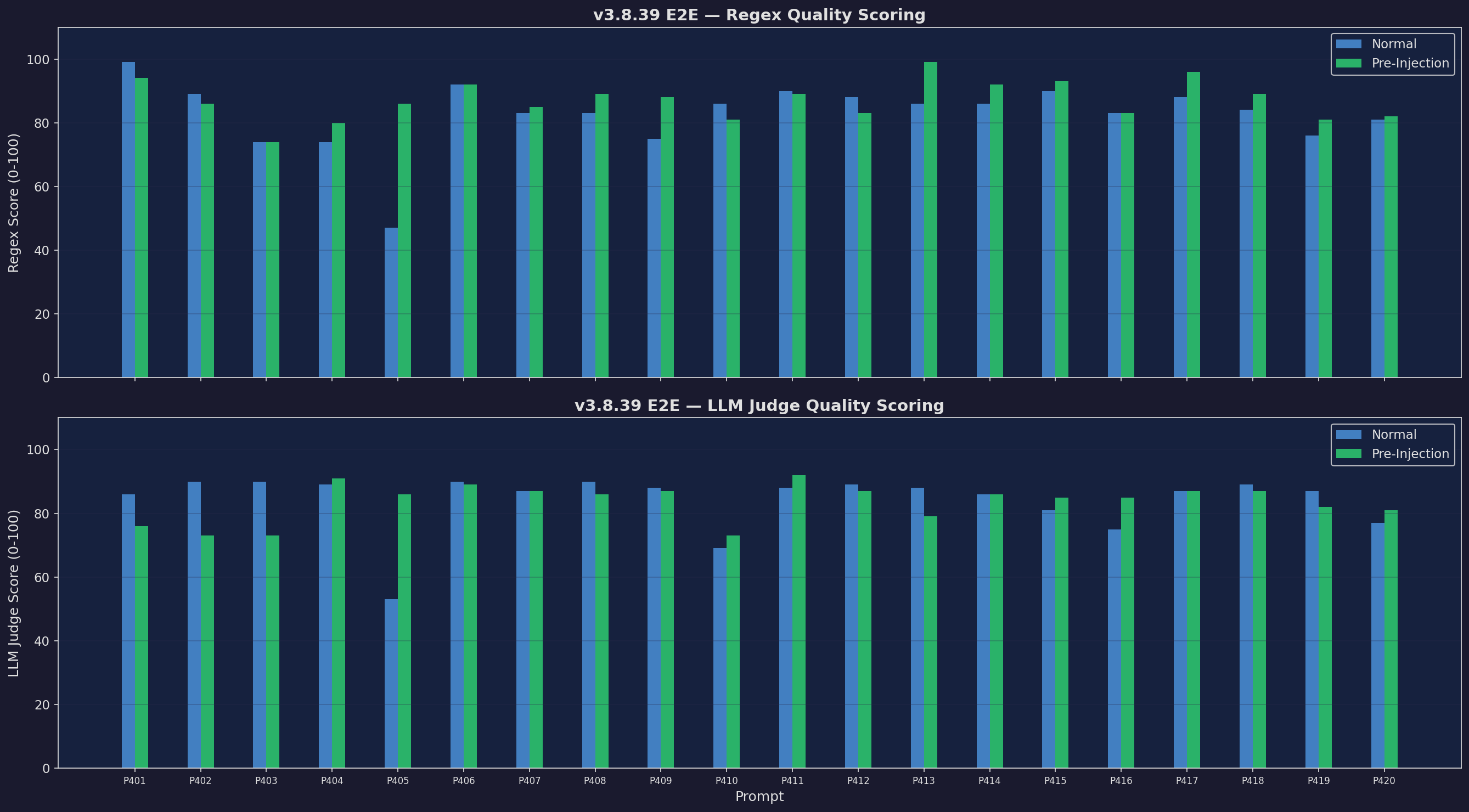
E2E Quality (Regex + LLM Judge)
Dual-scored quality — regex coverage + LLM judge
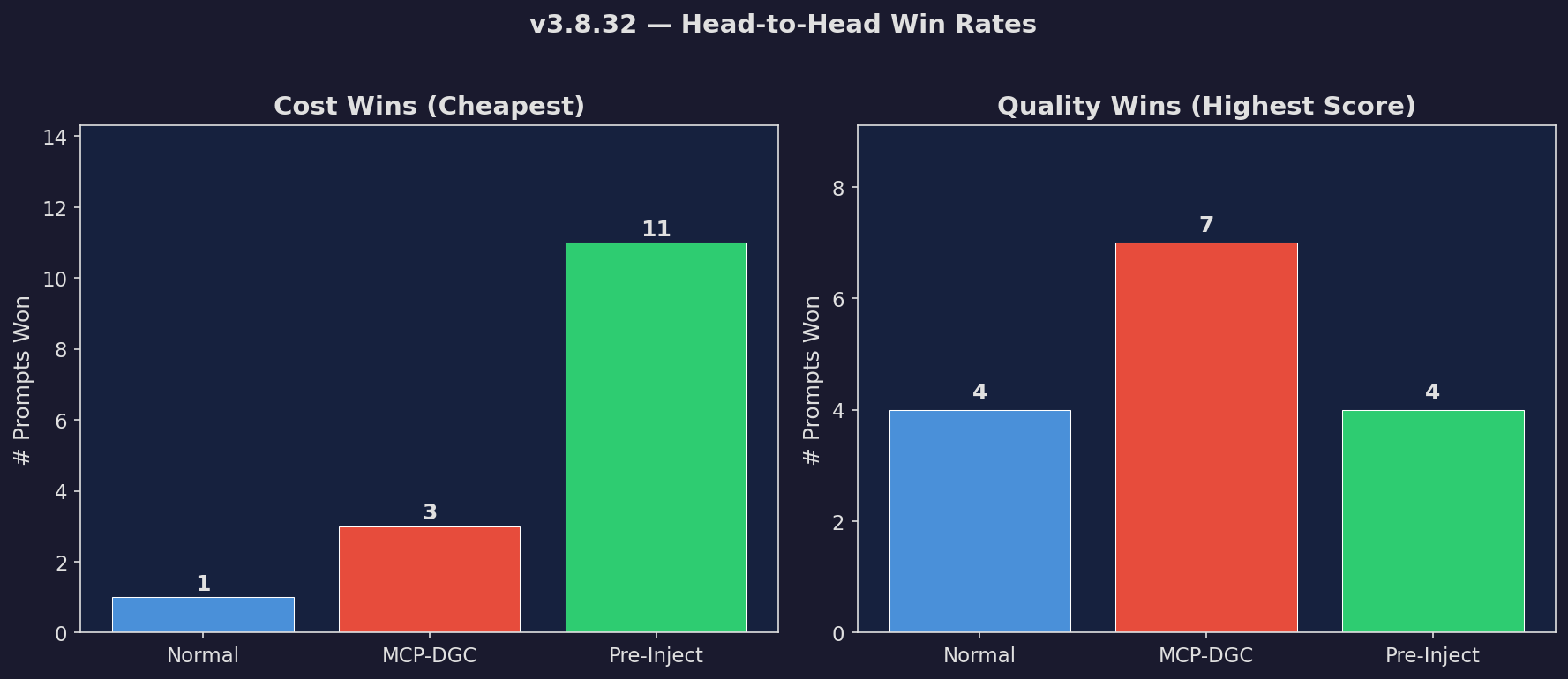
Win Rate Grid
Win/loss/tie breakdown across all versions
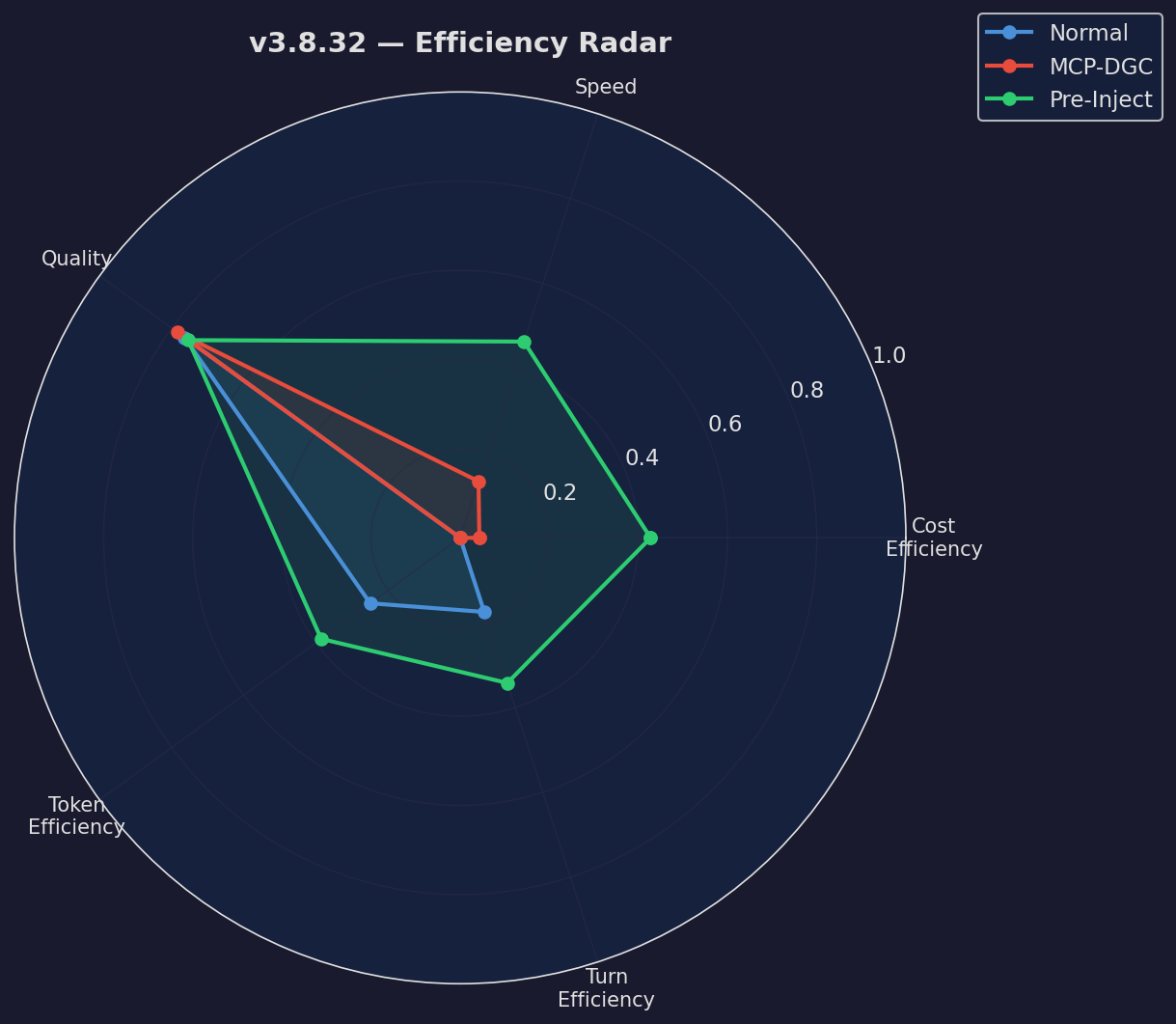
Efficiency Radar
Multi-dimensional efficiency comparison
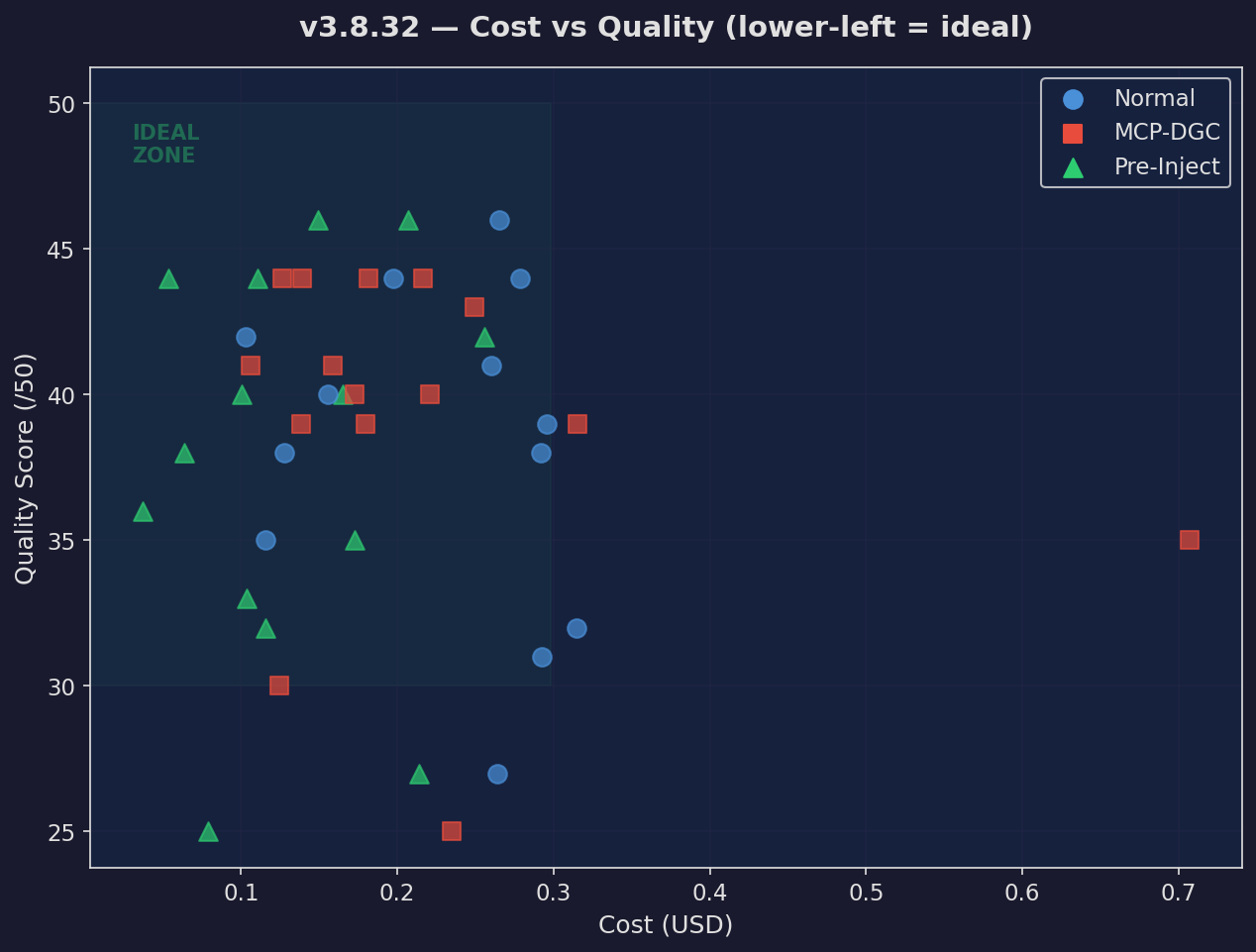
Cost vs Quality
Every prompt plotted: lower cost, higher quality
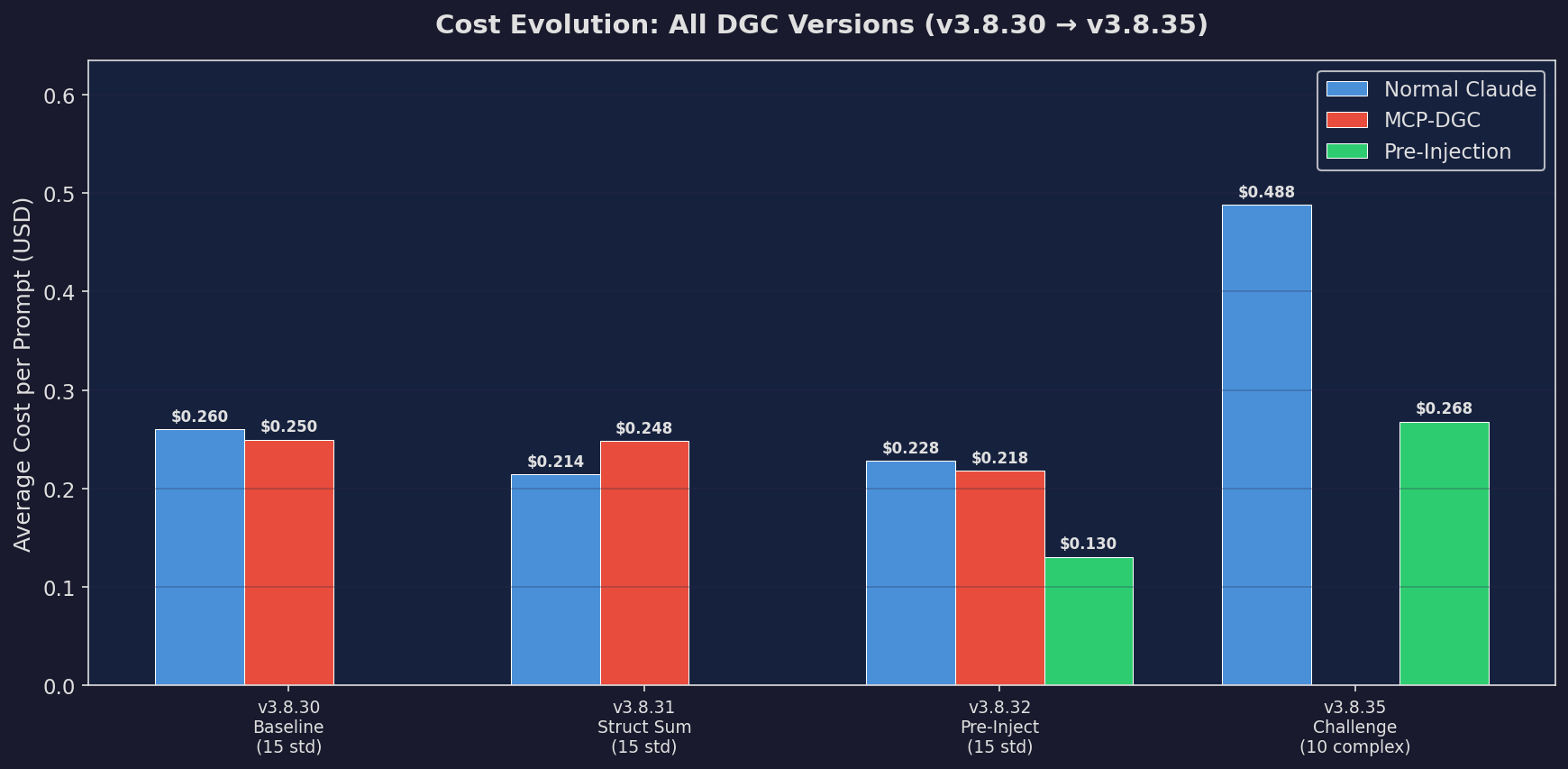
Cost Evolution (All Versions)
How each architecture iteration reduced cost
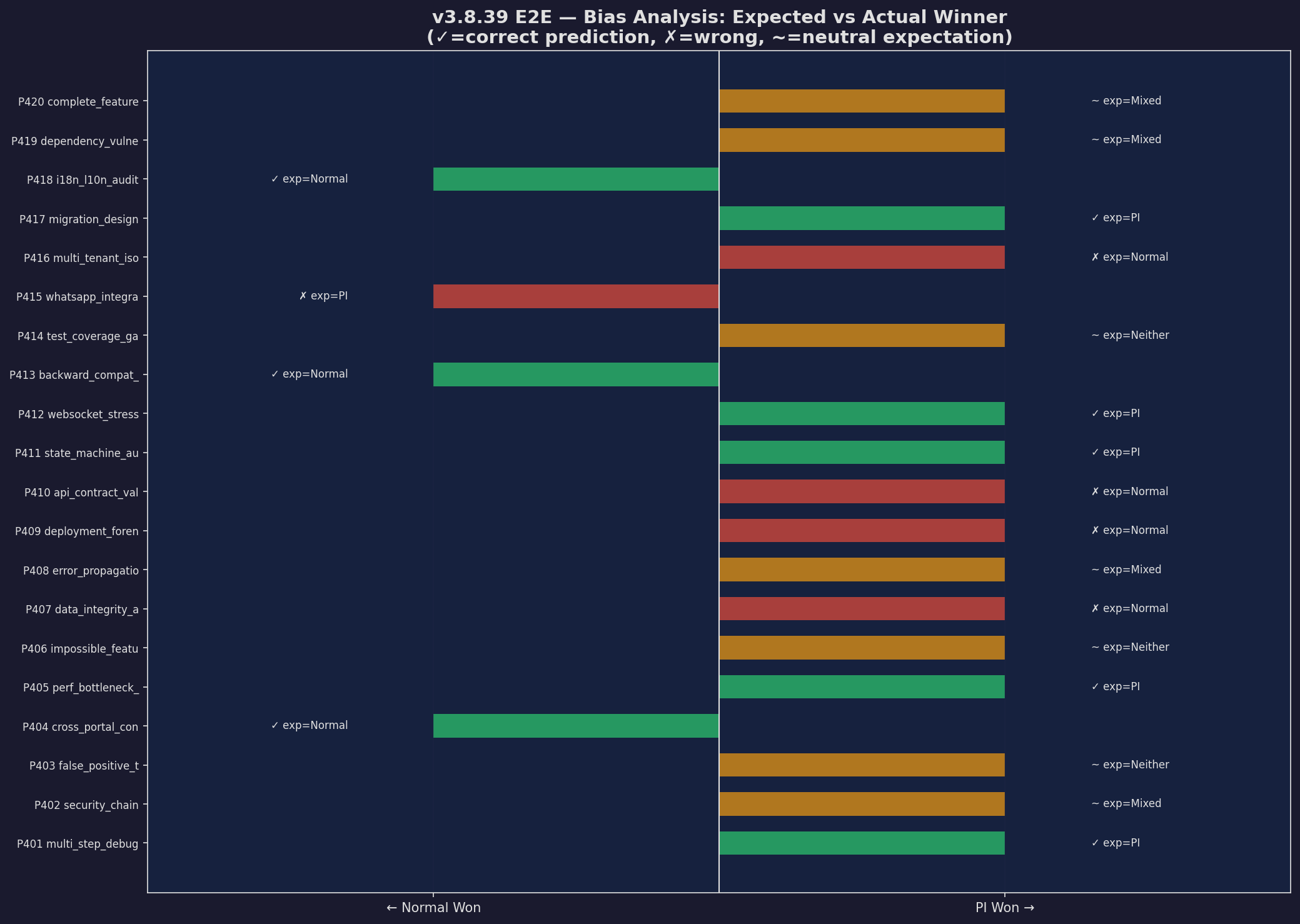
Bias Analysis
Expected vs actual winners — fair benchmark
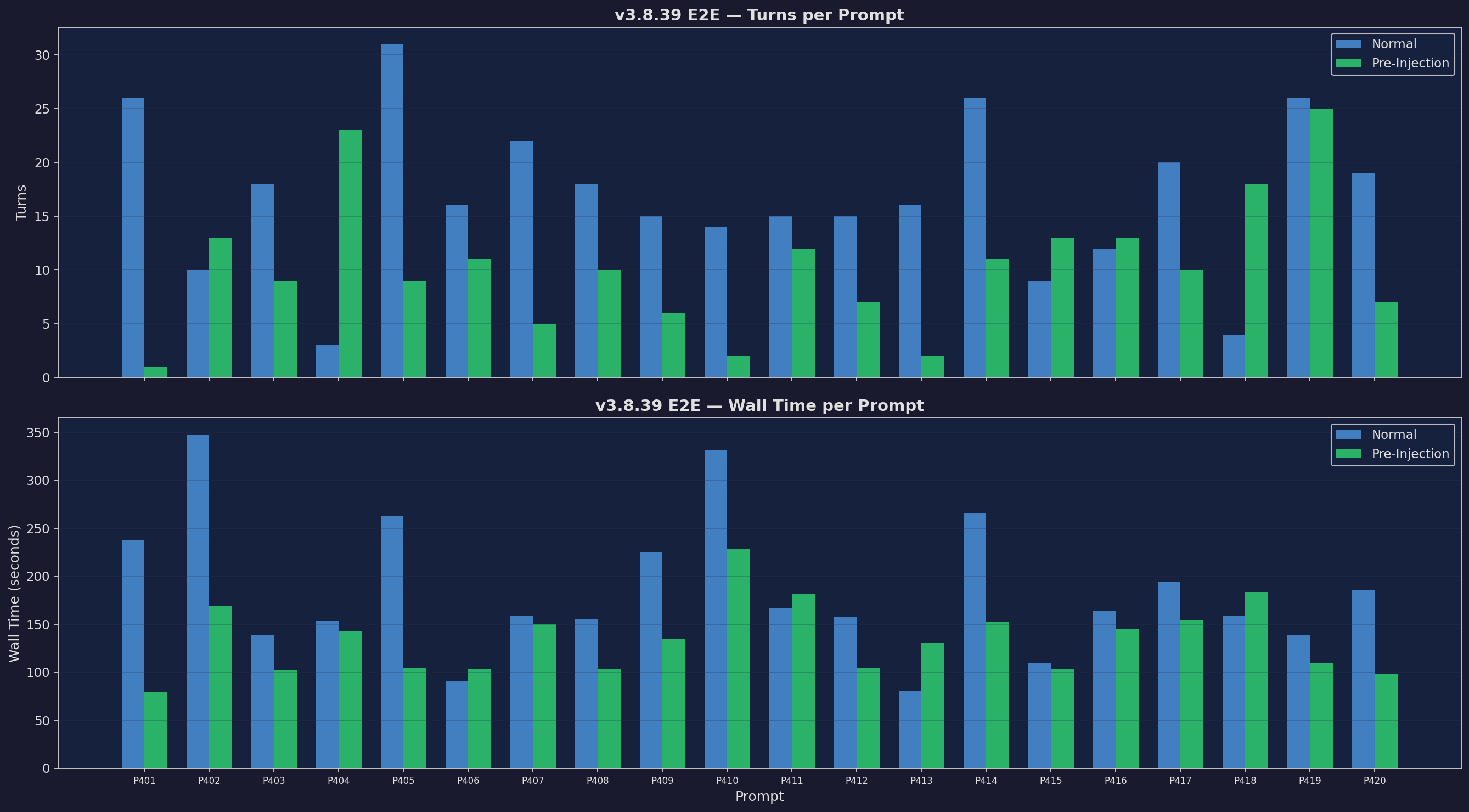
Turns & Wall Time (E2E)
Fewer turns, faster responses across 20 prompts