Benchmarks
Does it actually work? We ran the numbers.
5 benchmark runs · 80+ prompts · real 92-file production codebase · same model (Claude Sonnet 4.6), same questions — with and without GrapeRoot.
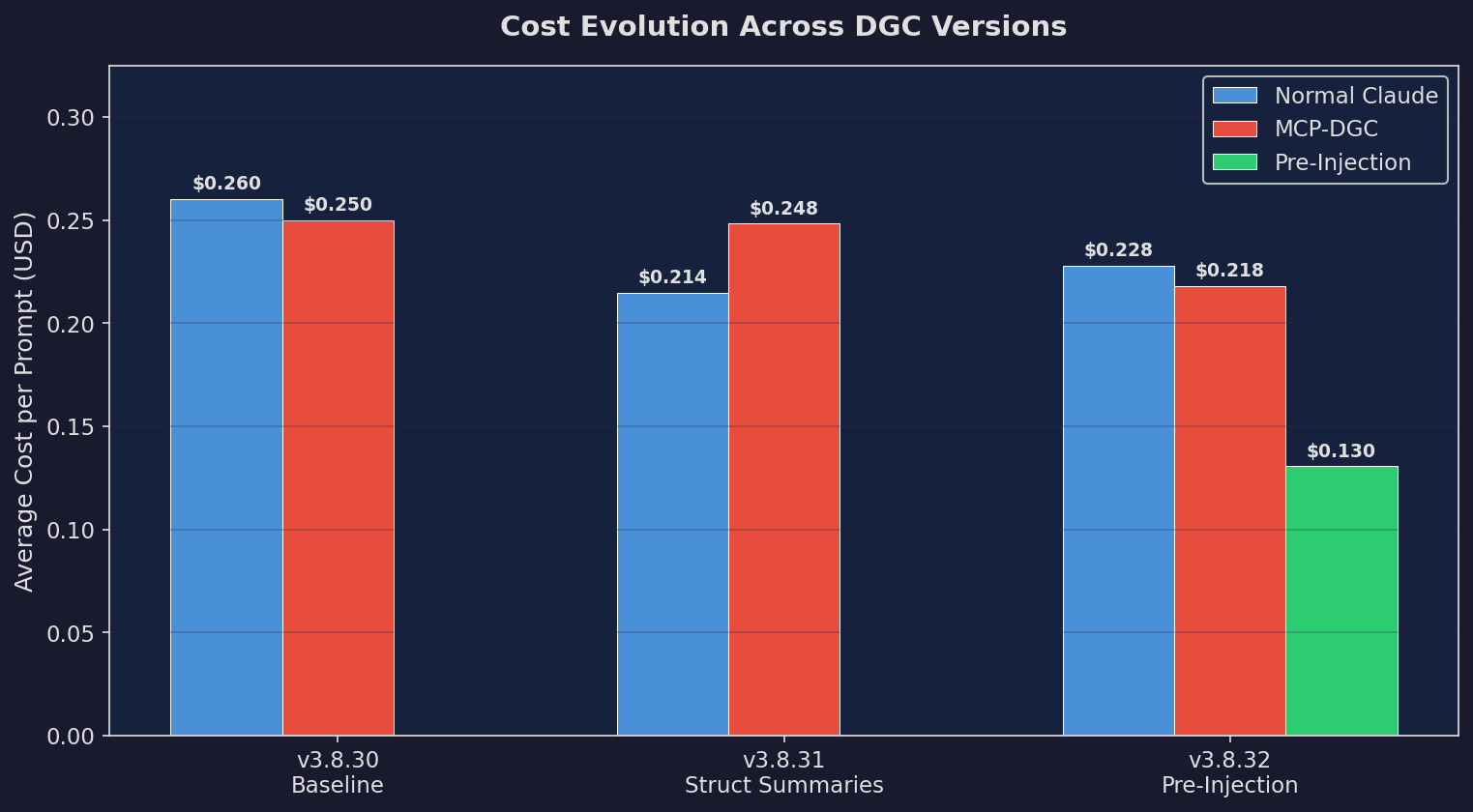
Cost Evolution
Cost over version iterations
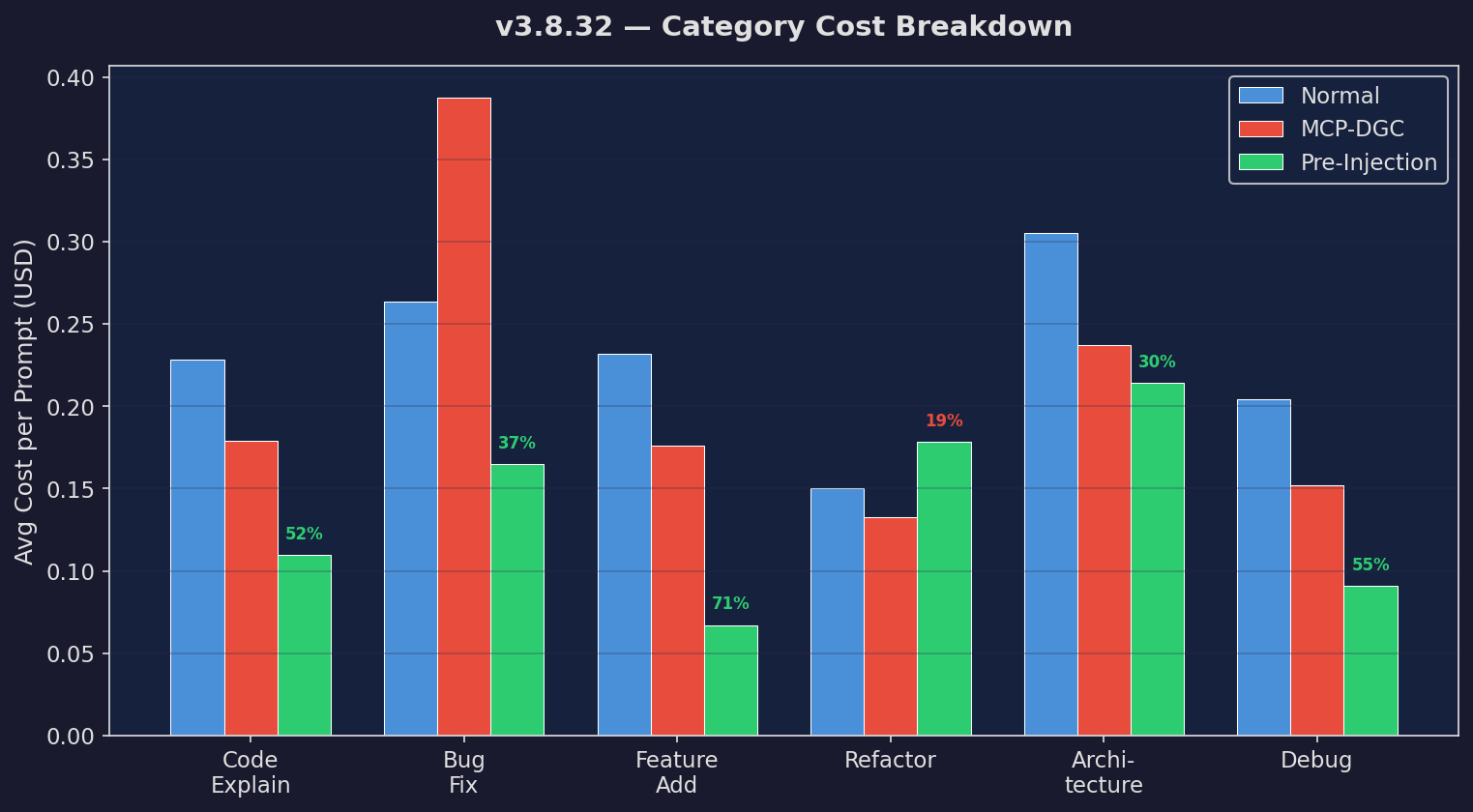
Category Cost
Cost by task category
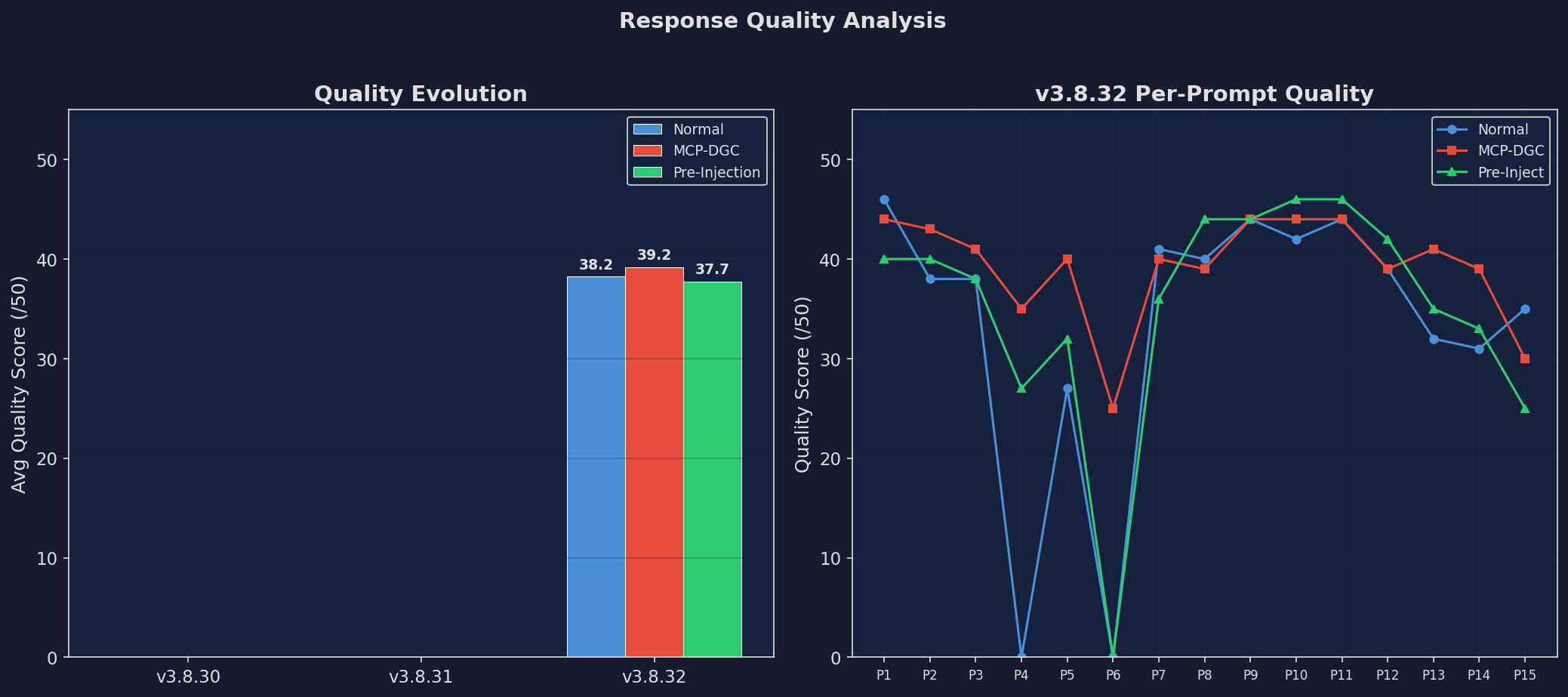
Quality Scores
Quality across versions
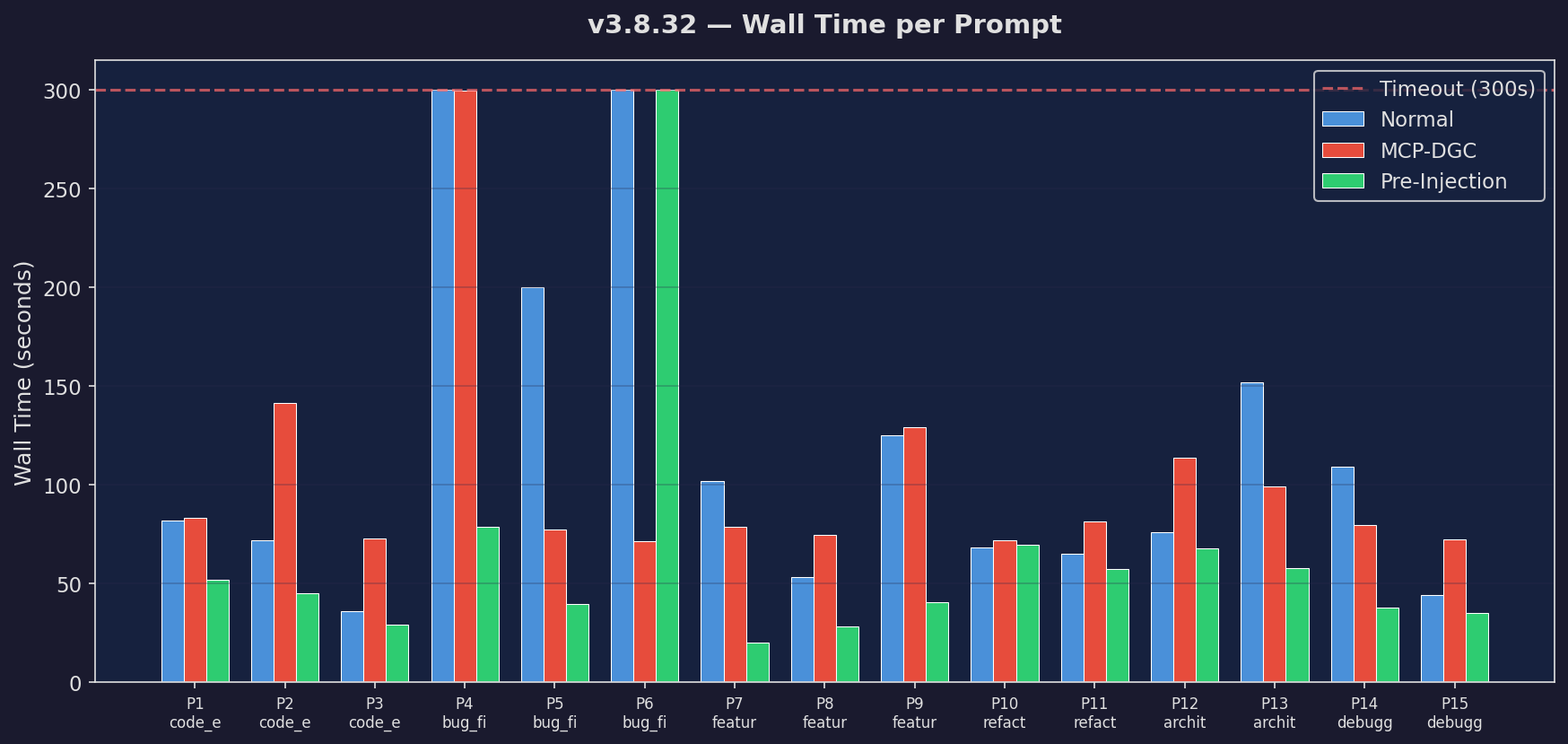
Wall Time
Latency comparison
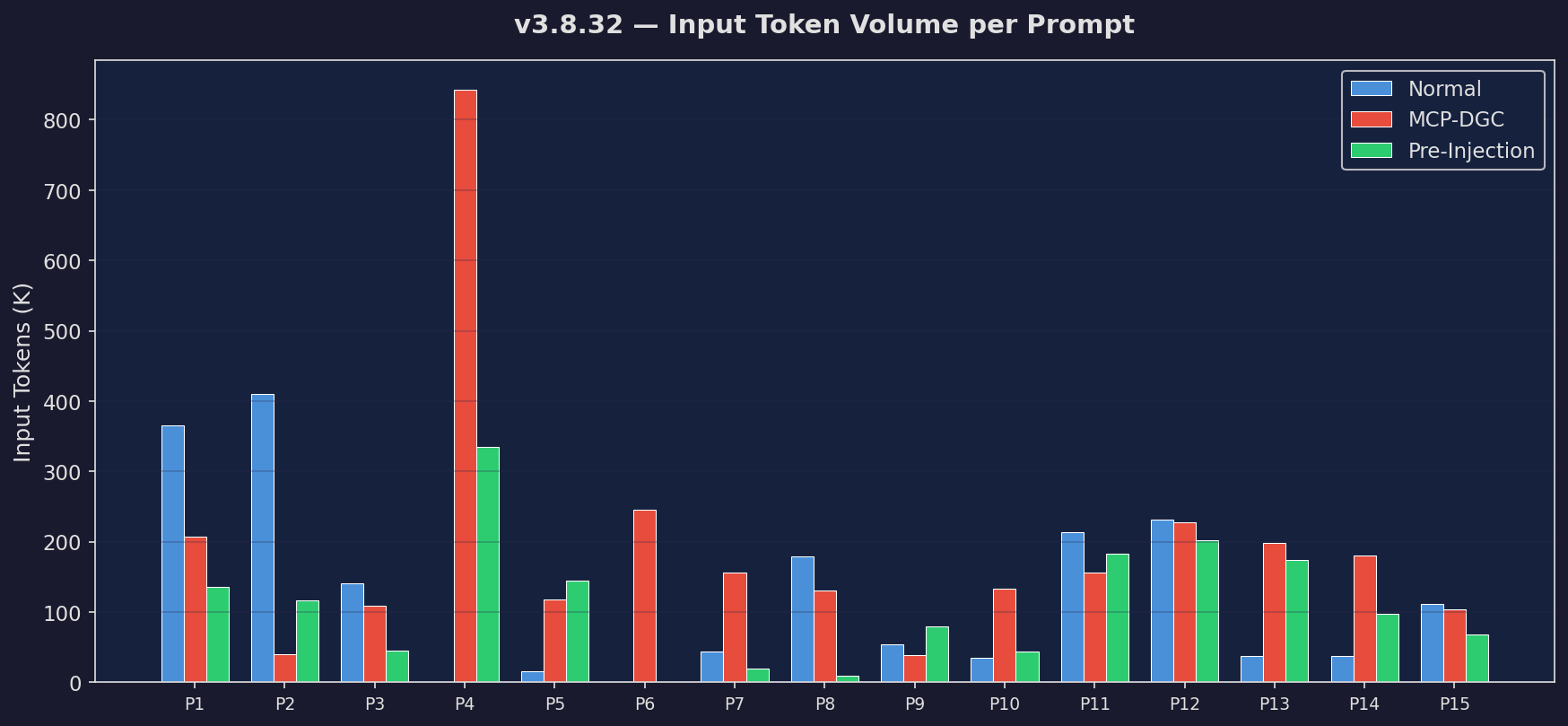
Token Volume
Input + output token usage
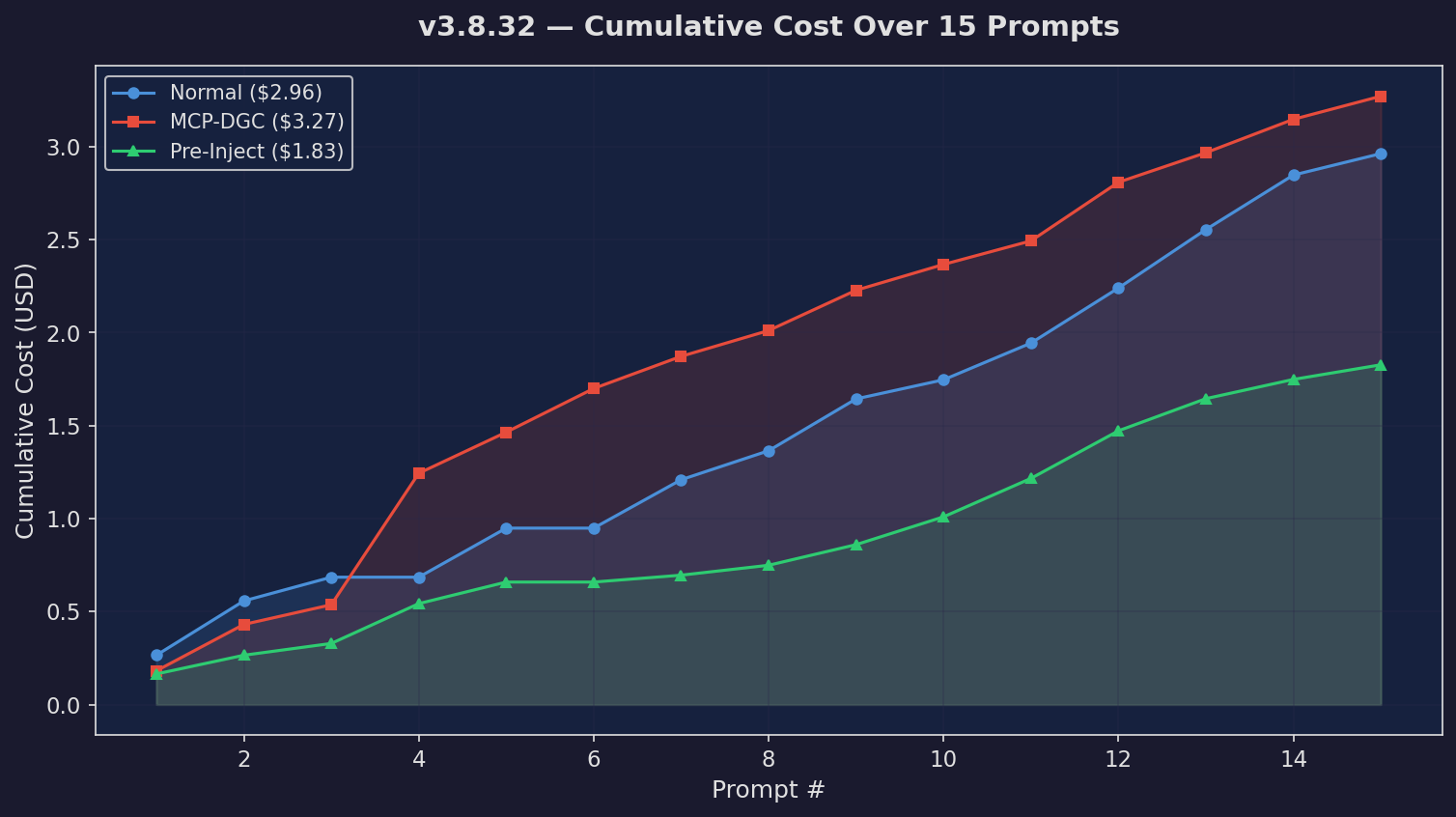
Cumulative Cost
Running cost across prompts
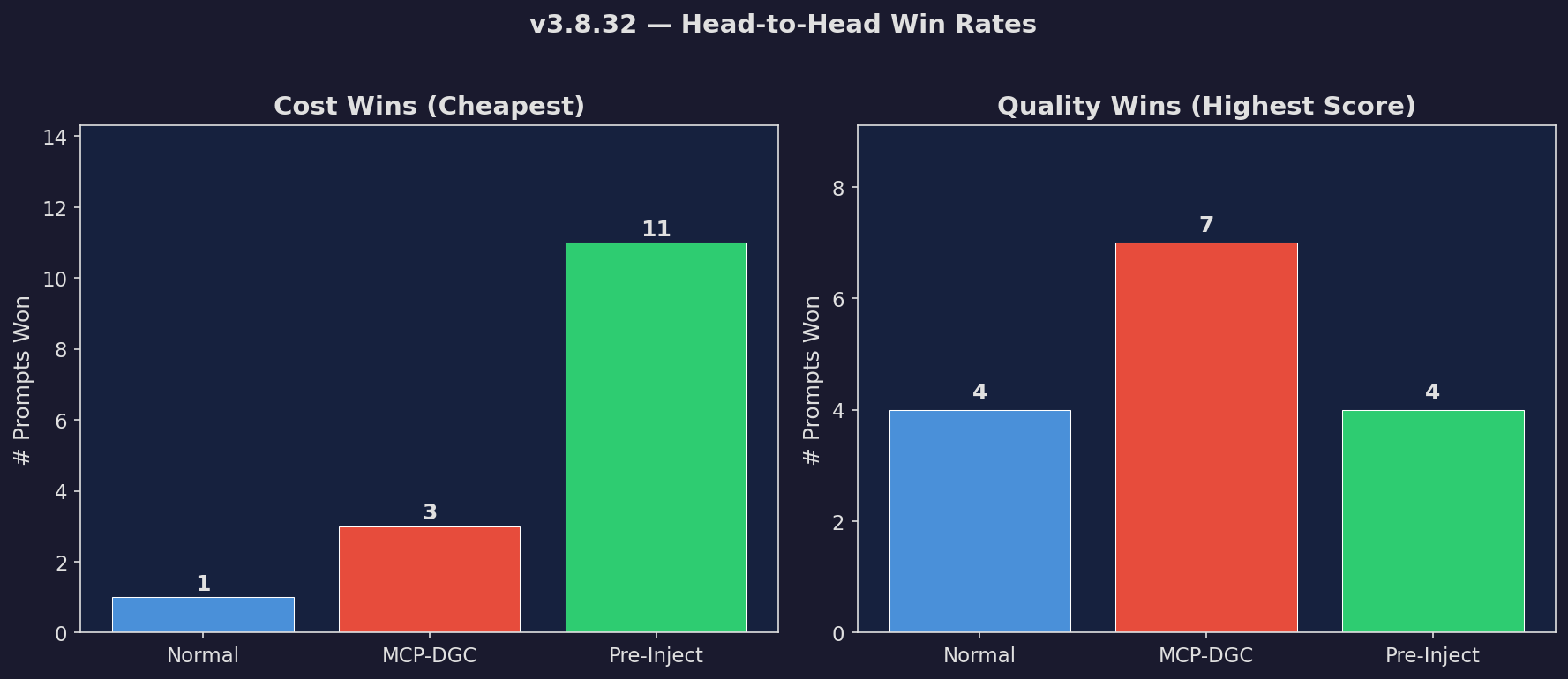
Win Rate
Win/loss/tie breakdown
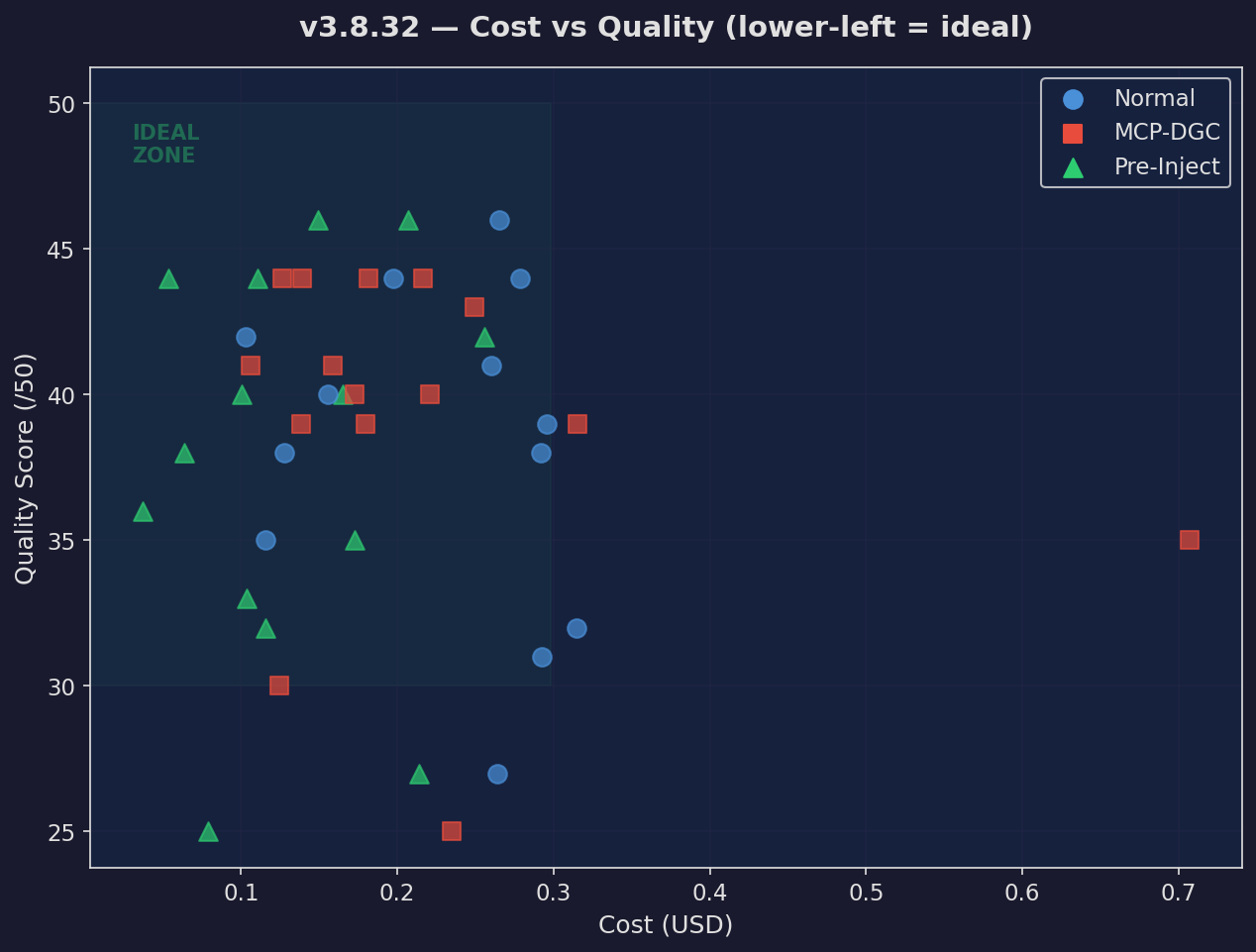
Cost vs Quality
Every prompt plotted
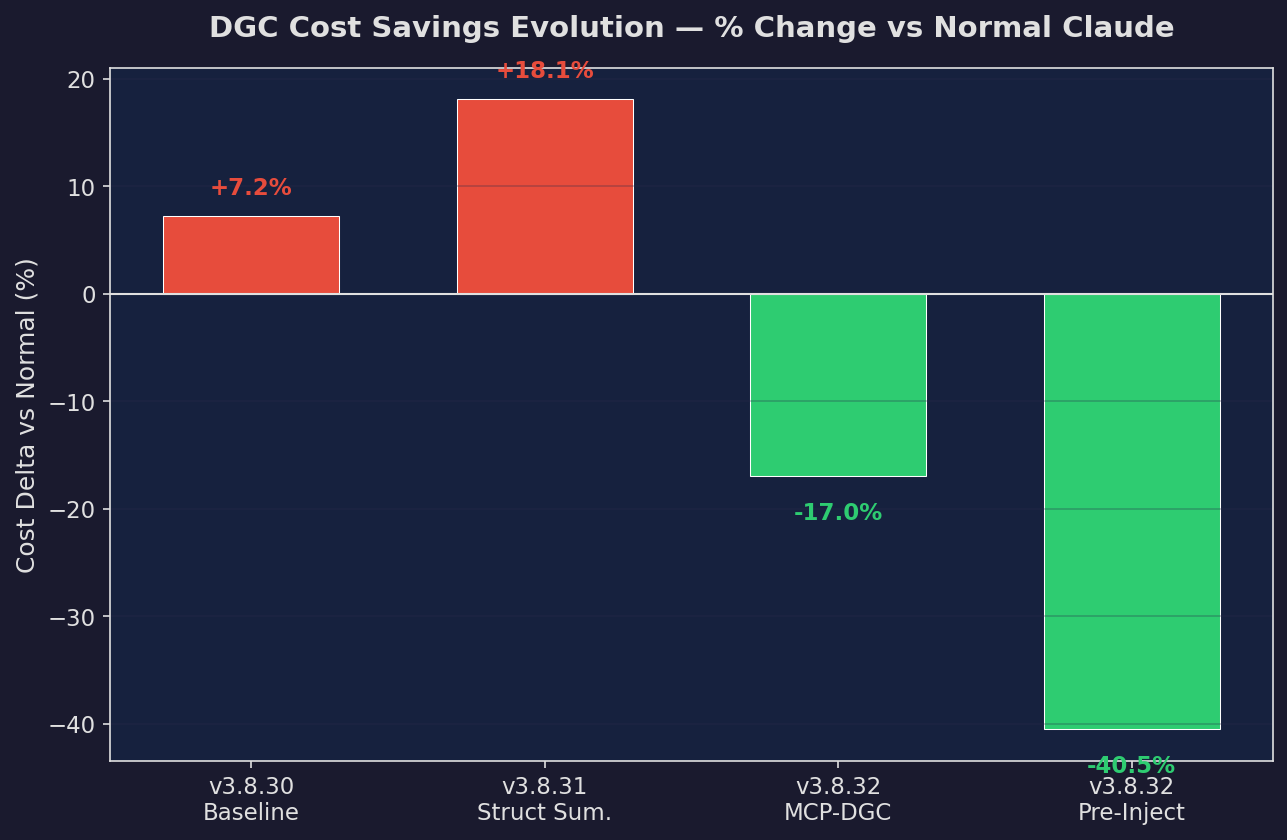
Version Delta
Change vs prior version
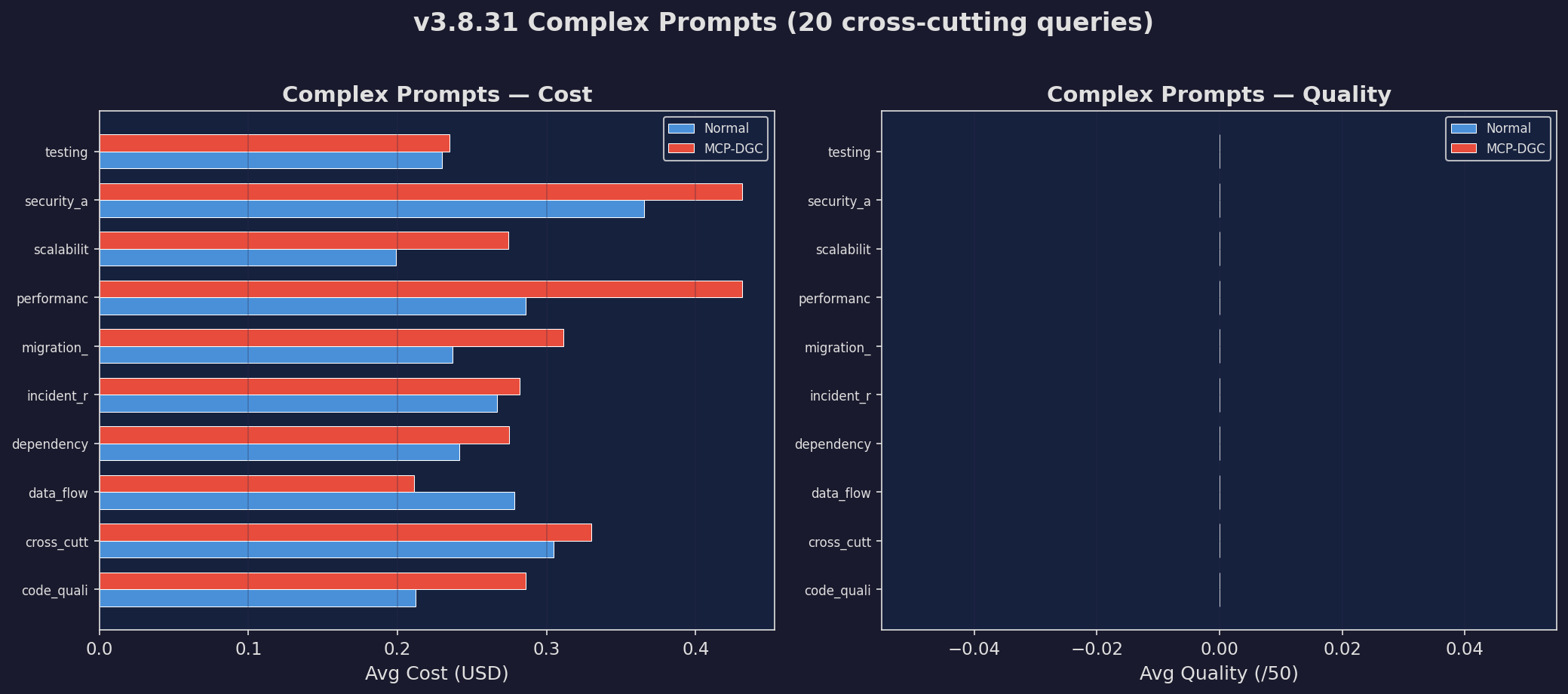
Complex Prompts
Hardest prompt subset
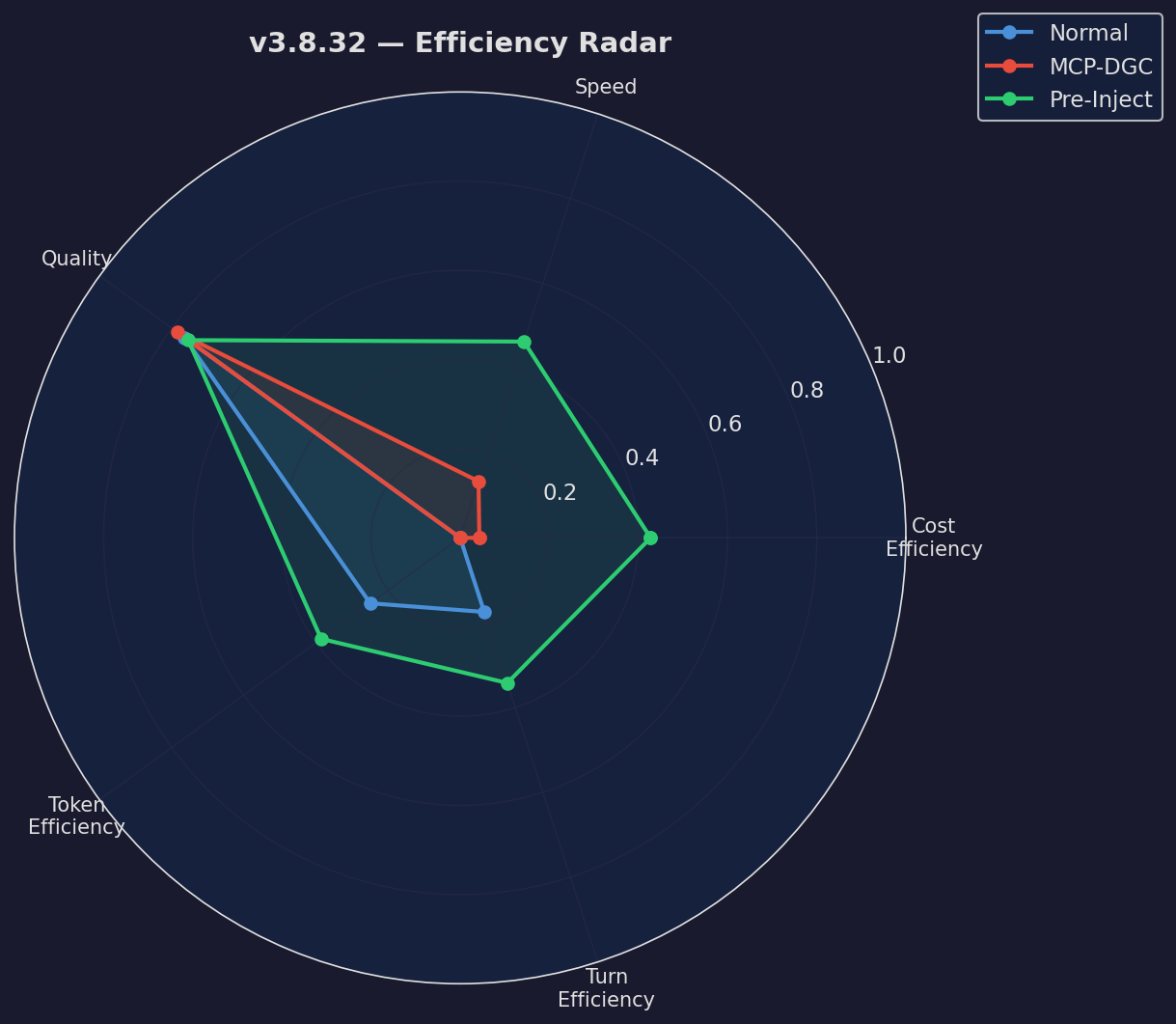
Efficiency Radar
Multi-dimensional comparison
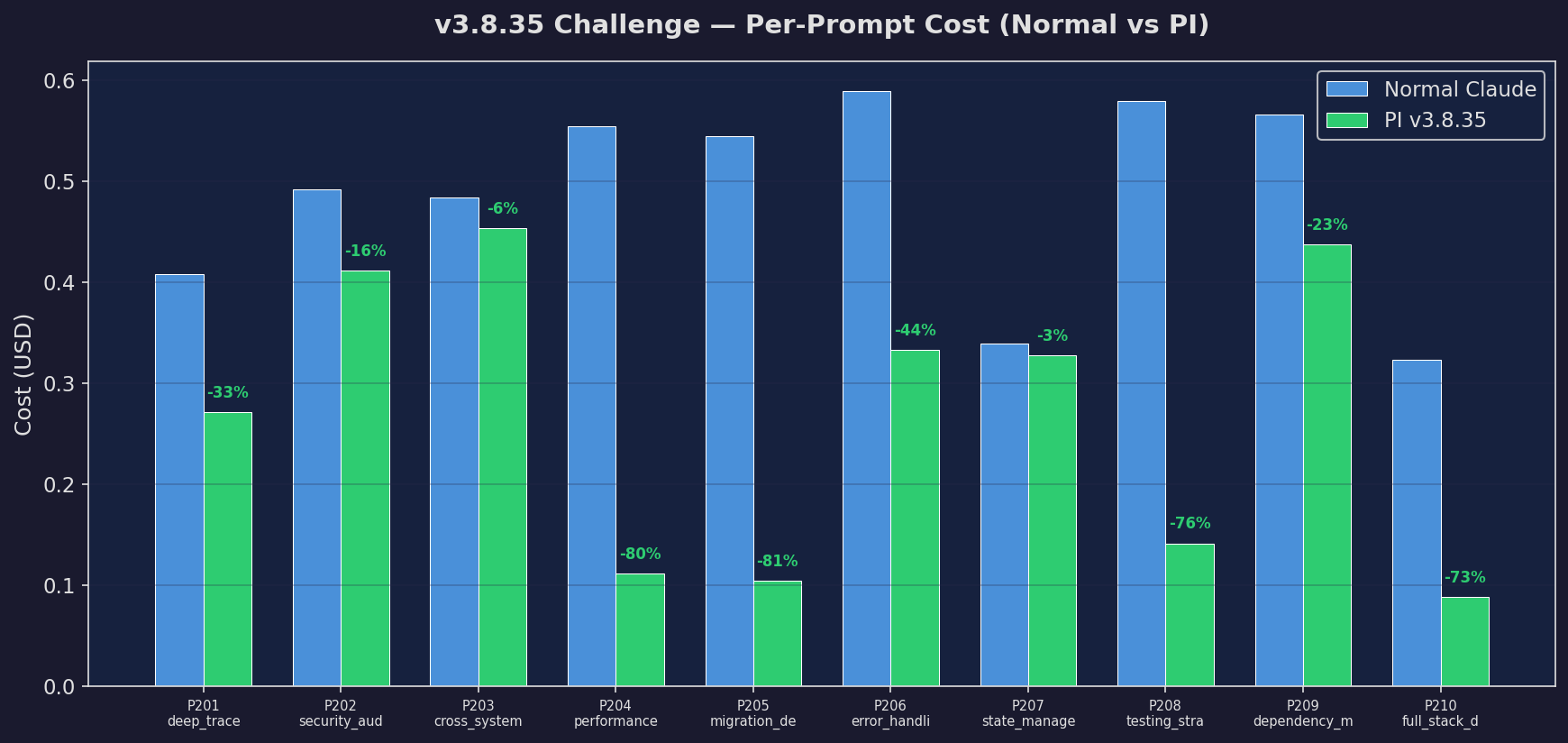
Challenge: Cost
Cost on challenge set
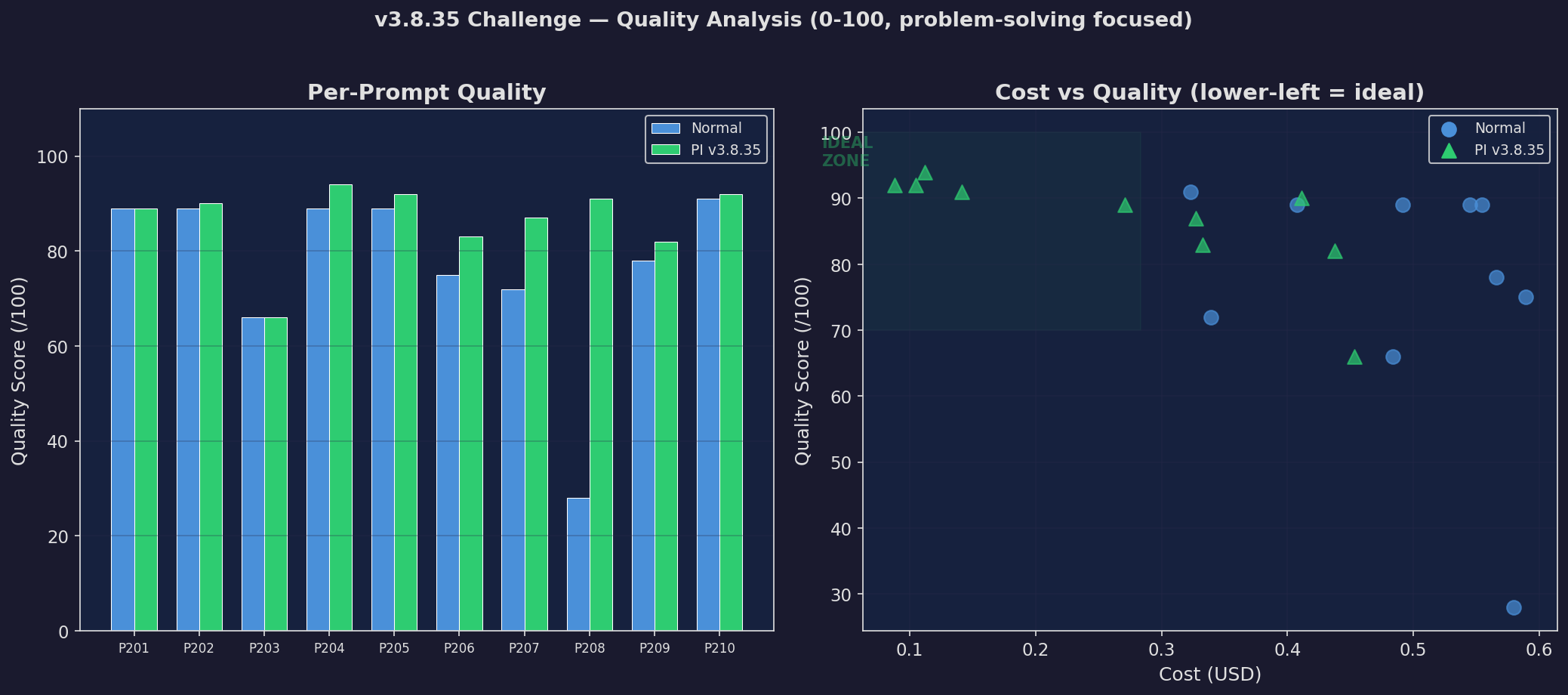
Challenge: Quality
Quality on challenge set
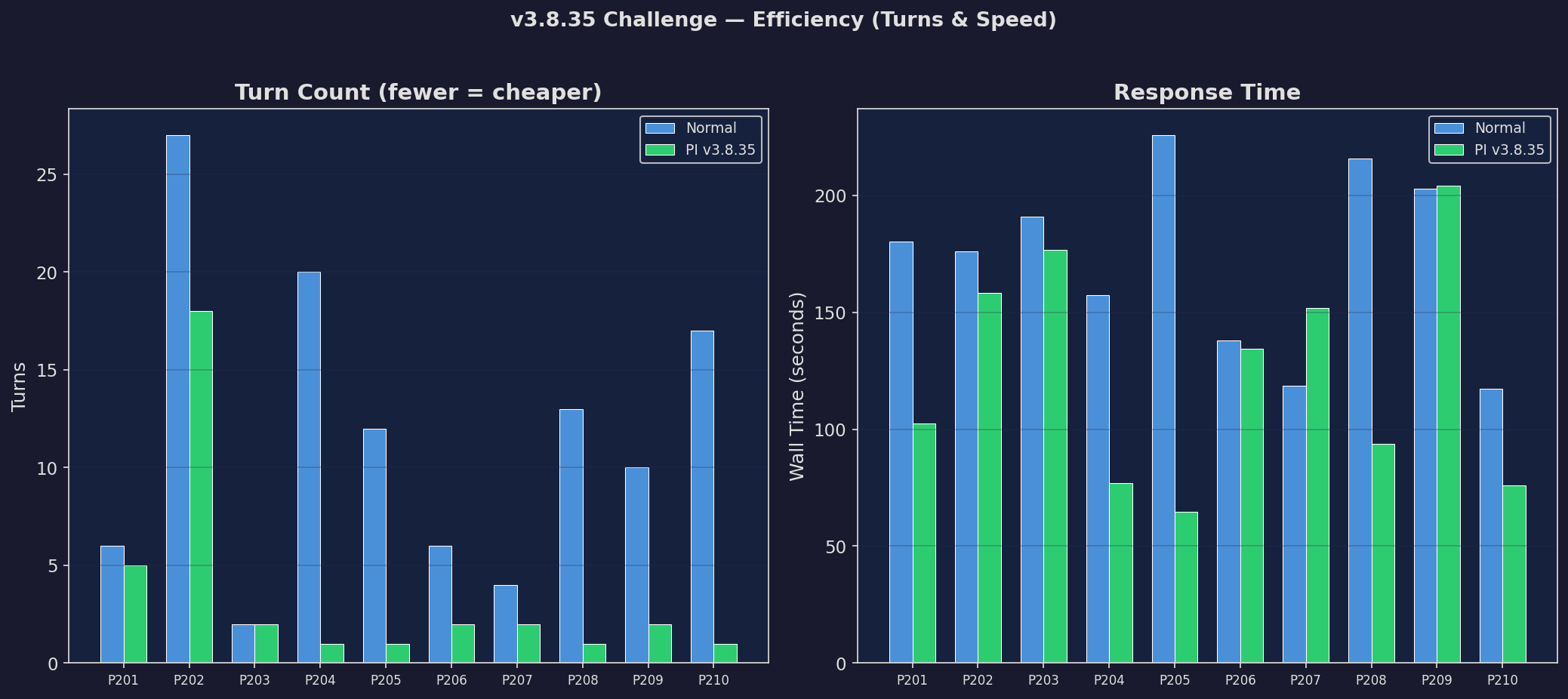
Challenge: Efficiency
Efficiency on challenge set
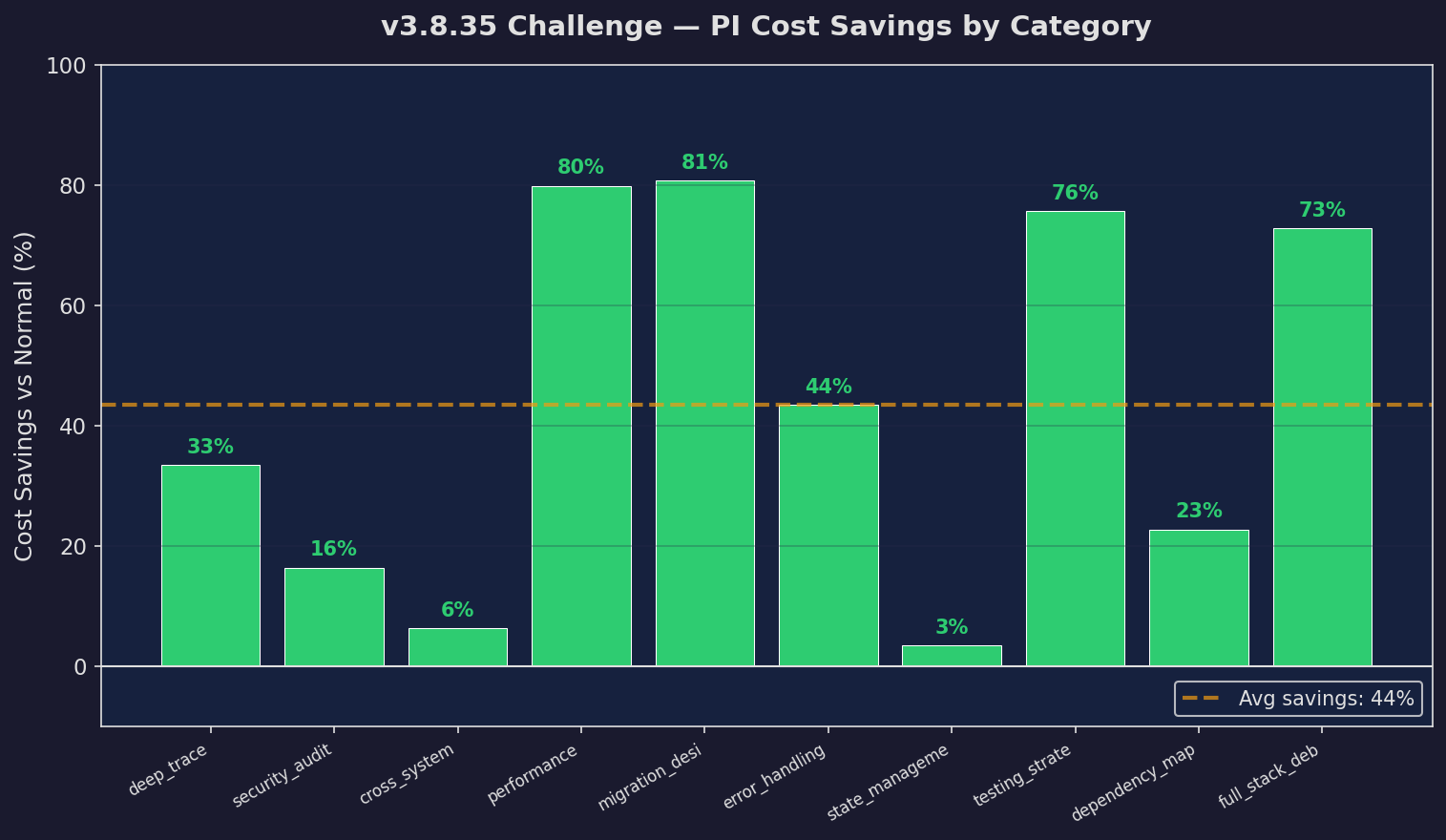
Challenge: Savings
Savings on challenge set
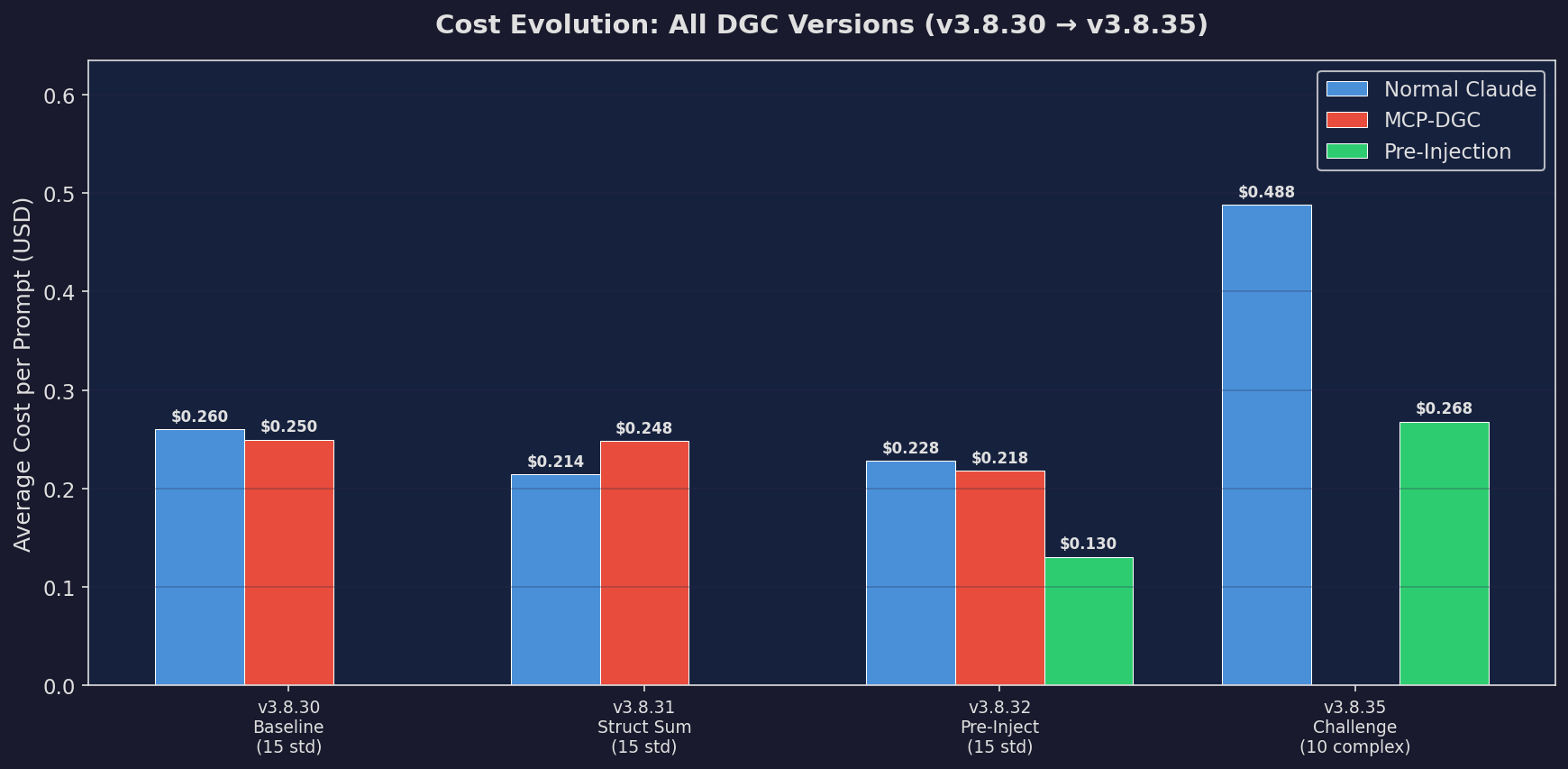
Full Cost Evolution
All versions, all costs
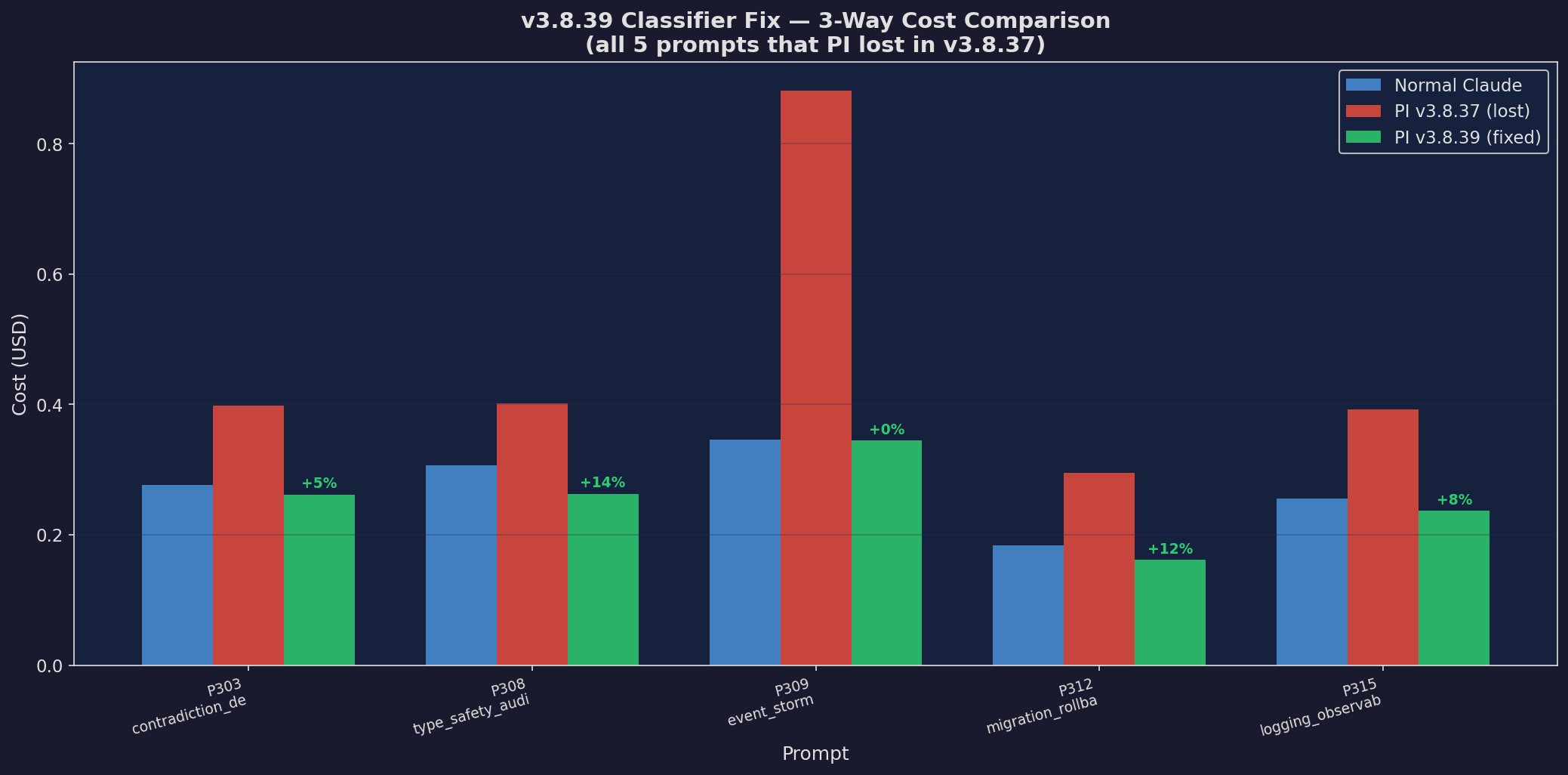
v3.8.39: 3-Way Cost
Three-way cost comparison
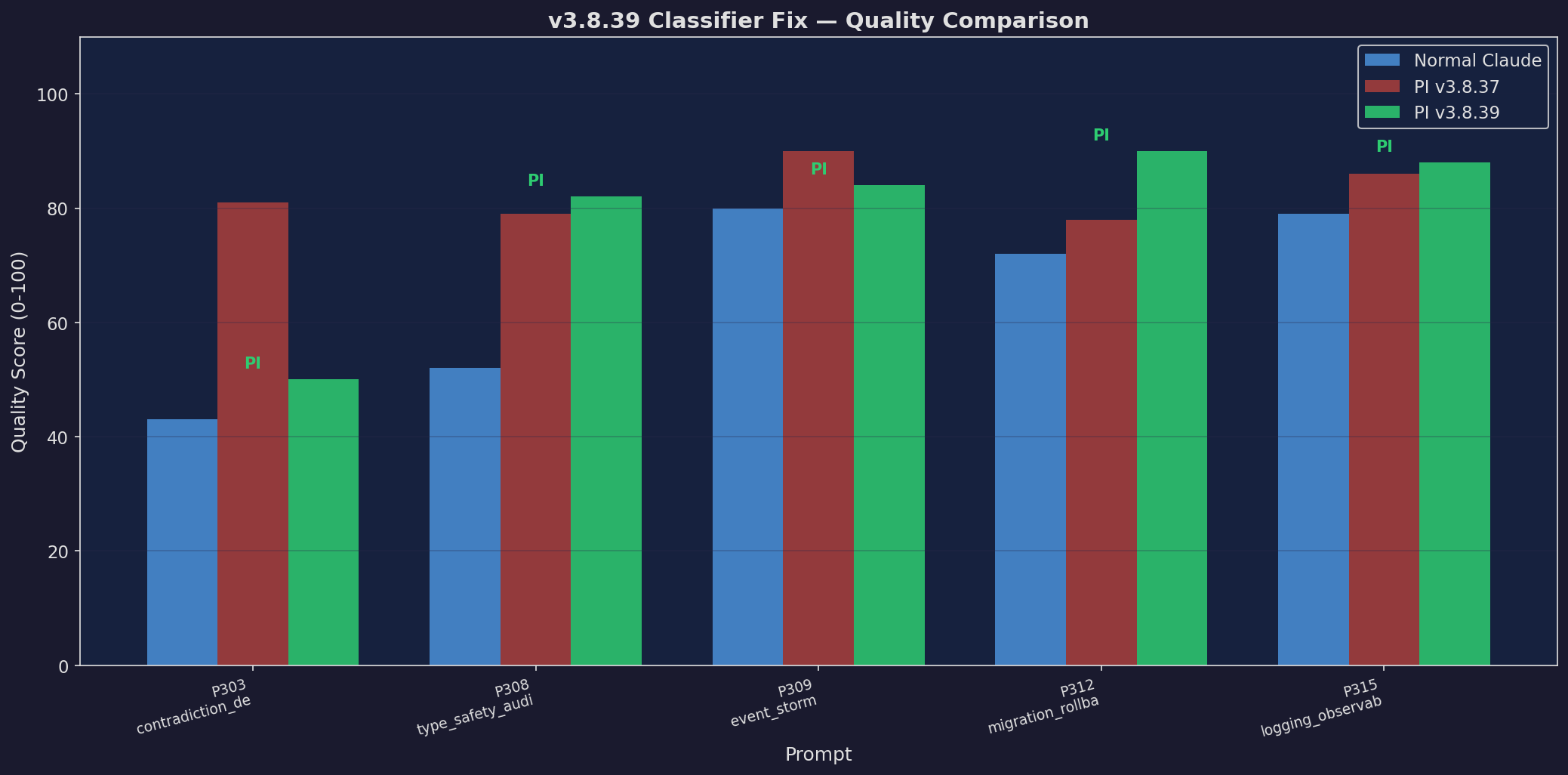
v3.8.39: 3-Way Quality
Three-way quality comparison
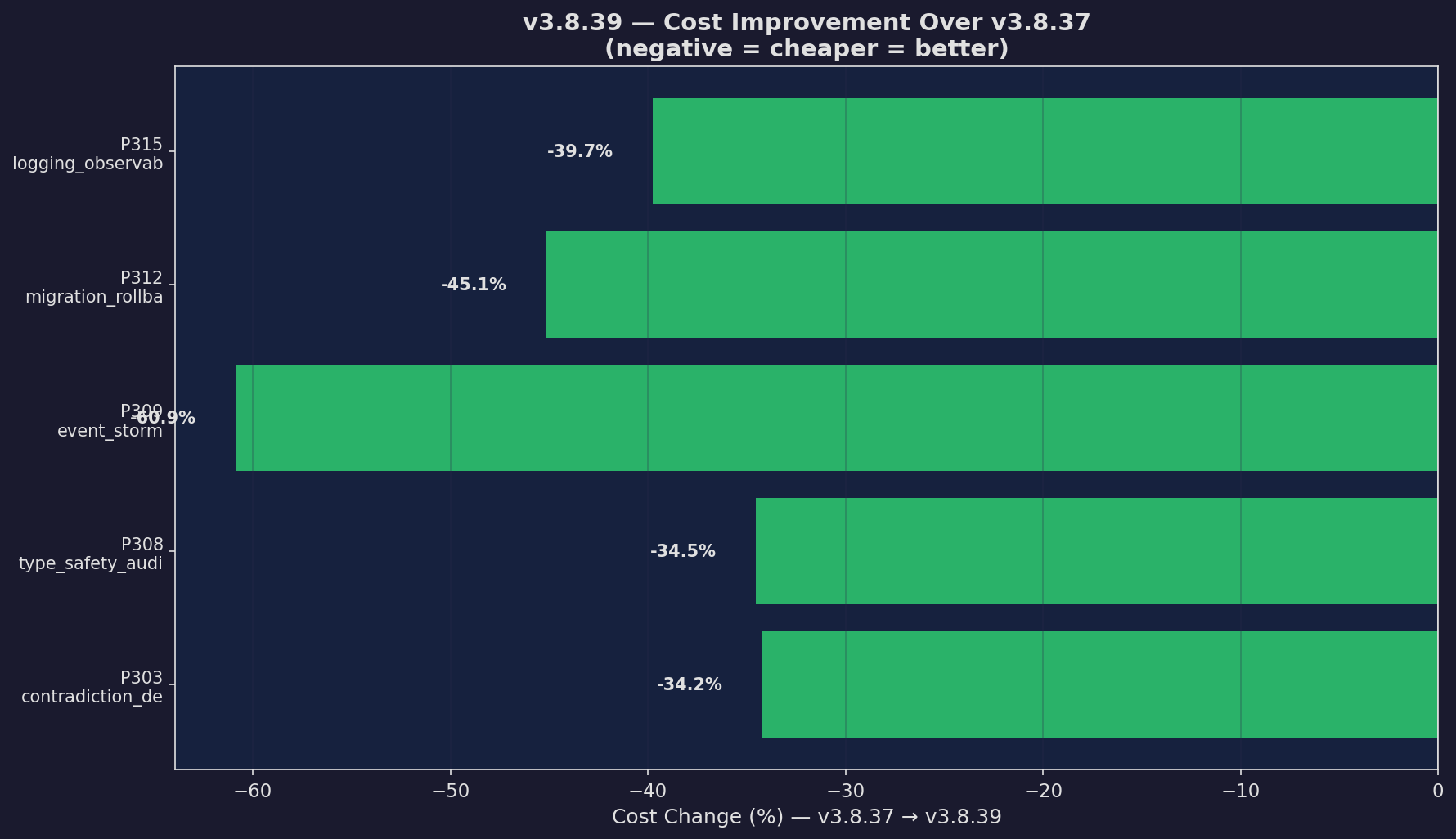
v3.8.39: Cost Improvement
Cost delta from prior version
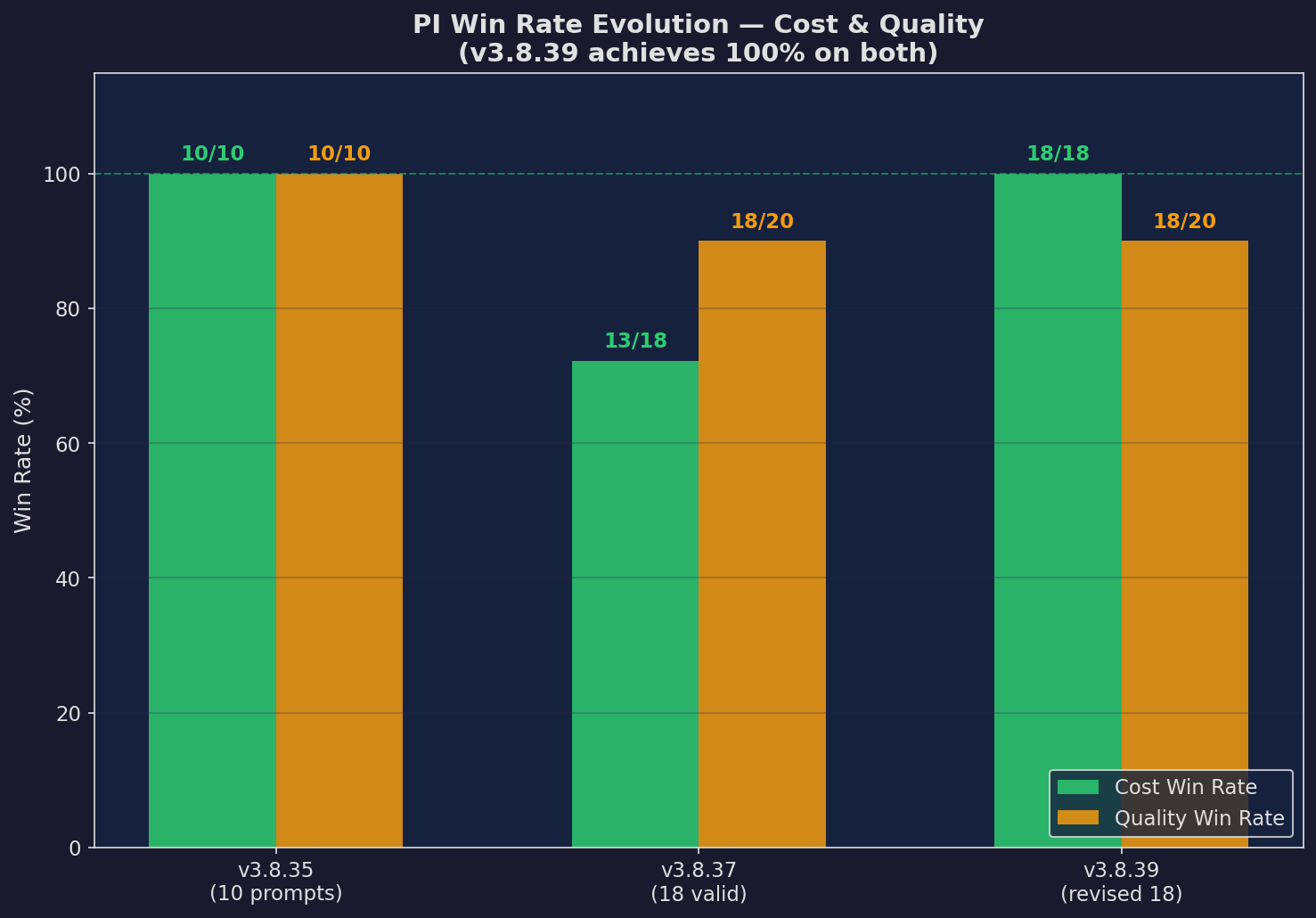
v3.8.39: Win Rate
Win rate for v3.8.39
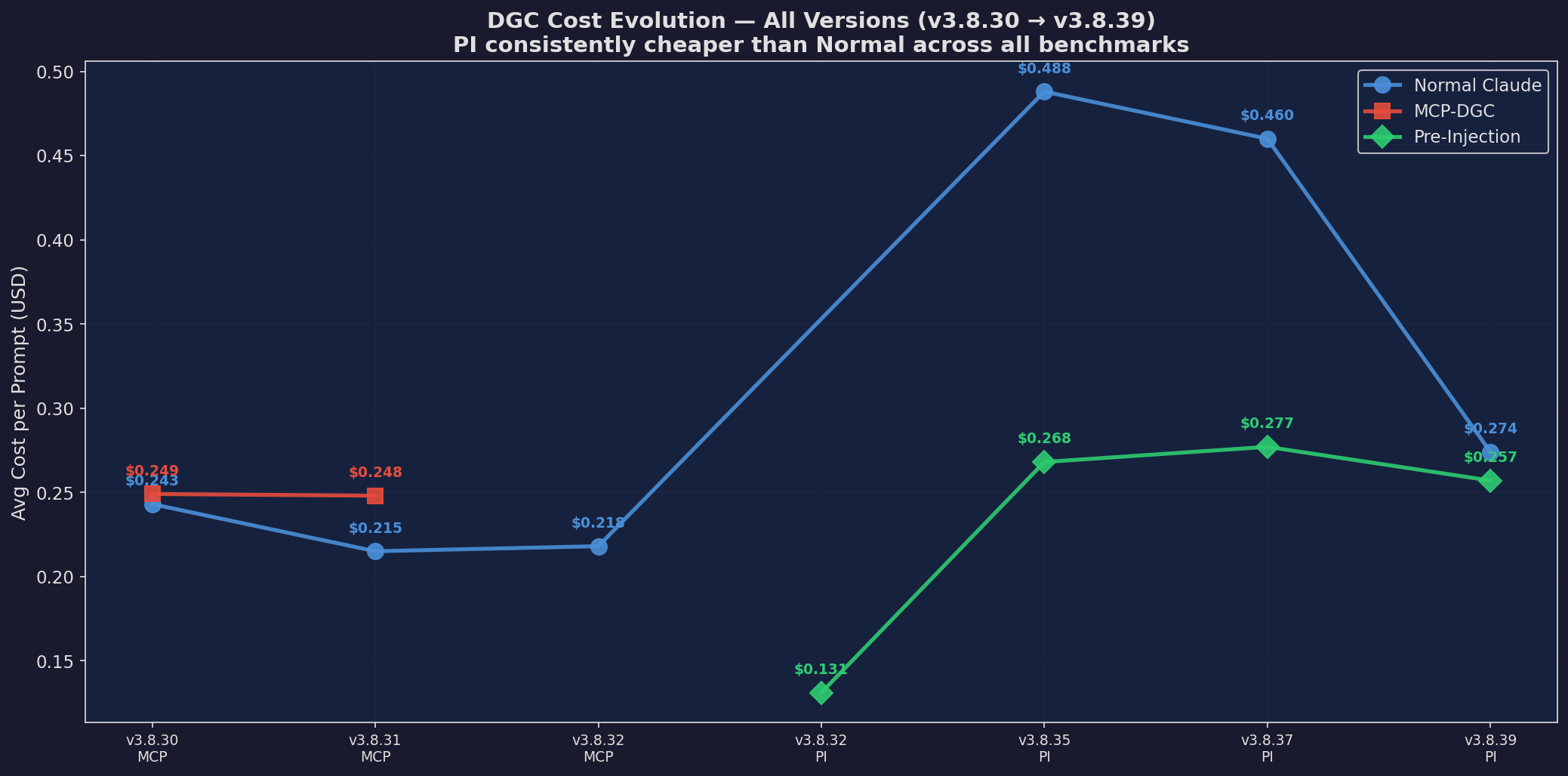
v3.8.39: Full Evolution
Full version cost evolution
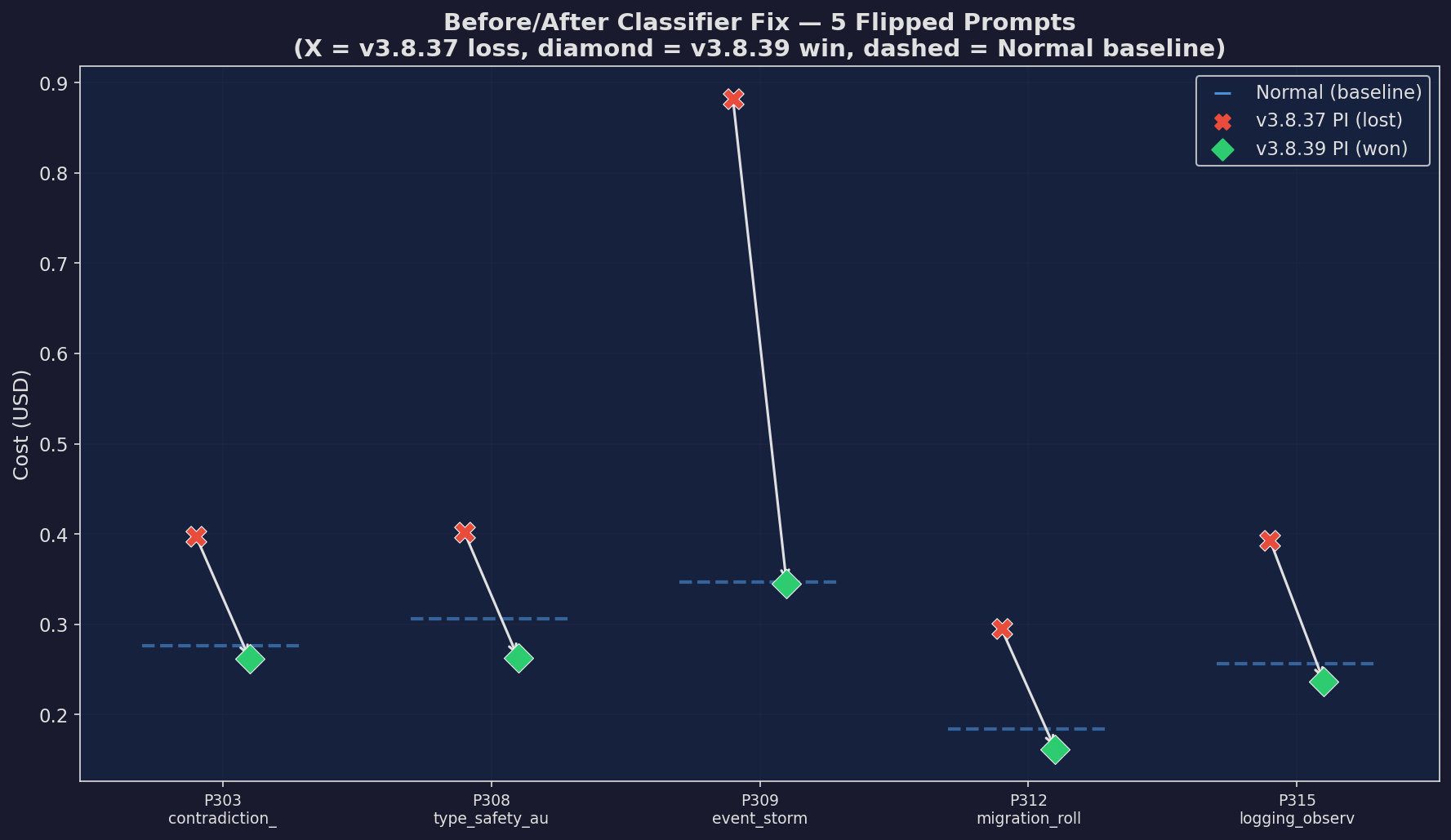
v3.8.39: Before/After
Before/after comparison