Benchmarks
Does it actually work? We ran the numbers.
3 real production codebases · 78 prompts · TypeScript, Go, and Python · same model, same judge — with and without GrapeRoot.
Browse all benchmarks
GR Pro v6 vs Normal
Medusa (1,571 TS files) + Gitea (Go monorepo)
57%
cost saved
75%
quality wins
33
prompts
GR vs Boris vs JCM vs Normal
21 code-audit tasks · Medusa TypeScript
66%
GR cheaper vs Normal
21
prompts
4
tools
GR v3 — Sentry Python
getsentry/sentry · 7,762 Python files
53%
cost saved
24
prompts
7.7k
files
GrapeRoot Pro v6 vs Normal — Benchmark
NEW33 prompts · Medusa (TypeScript, 1,571 files) + Gitea (Go) · Claude Sonnet 4.6 · LLM judge
The question
GrapeRoot Pro v6 adds exhaustive enumeration tools — pre-computed dead exports, cycle detection via Tarjan SCC, and uncapped grep sweeps. Does this make it strictly better than running Claude with no context engine? We tested 33 prompts across two real codebases to find out.
GrapeRoot Pro v6
81.5
avg quality / 100
Normal (no tools)
77.6
avg quality / 100
Key Findings
75%
quality wins (25/33 prompts)
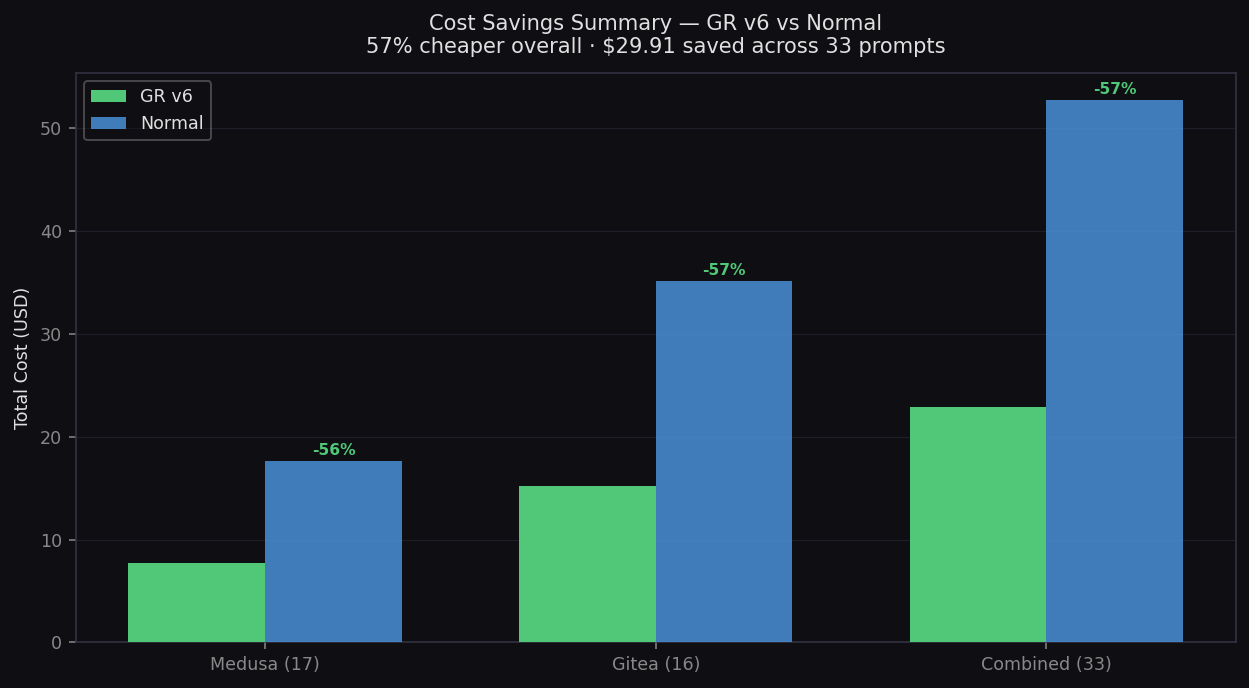
57%
cheaper ($0.69 vs $1.60)
+3.9
higher quality (81.5 vs 77.6)
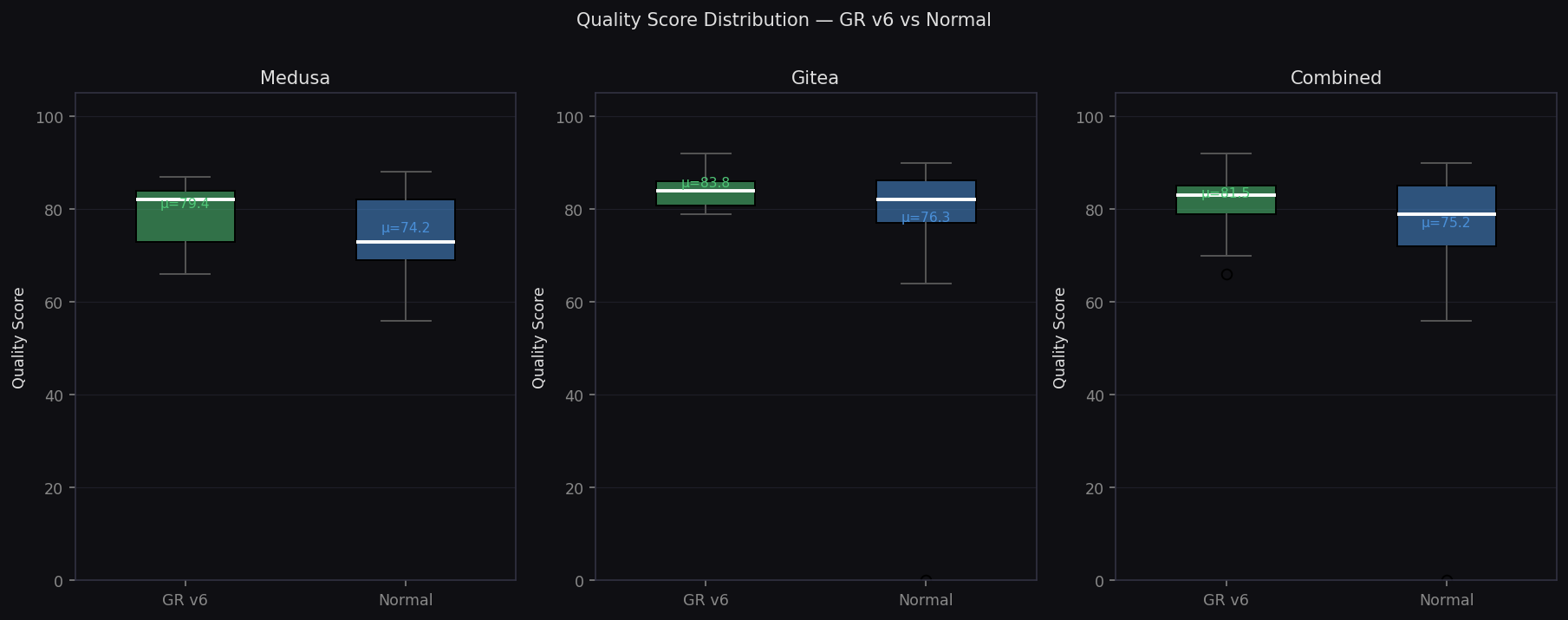
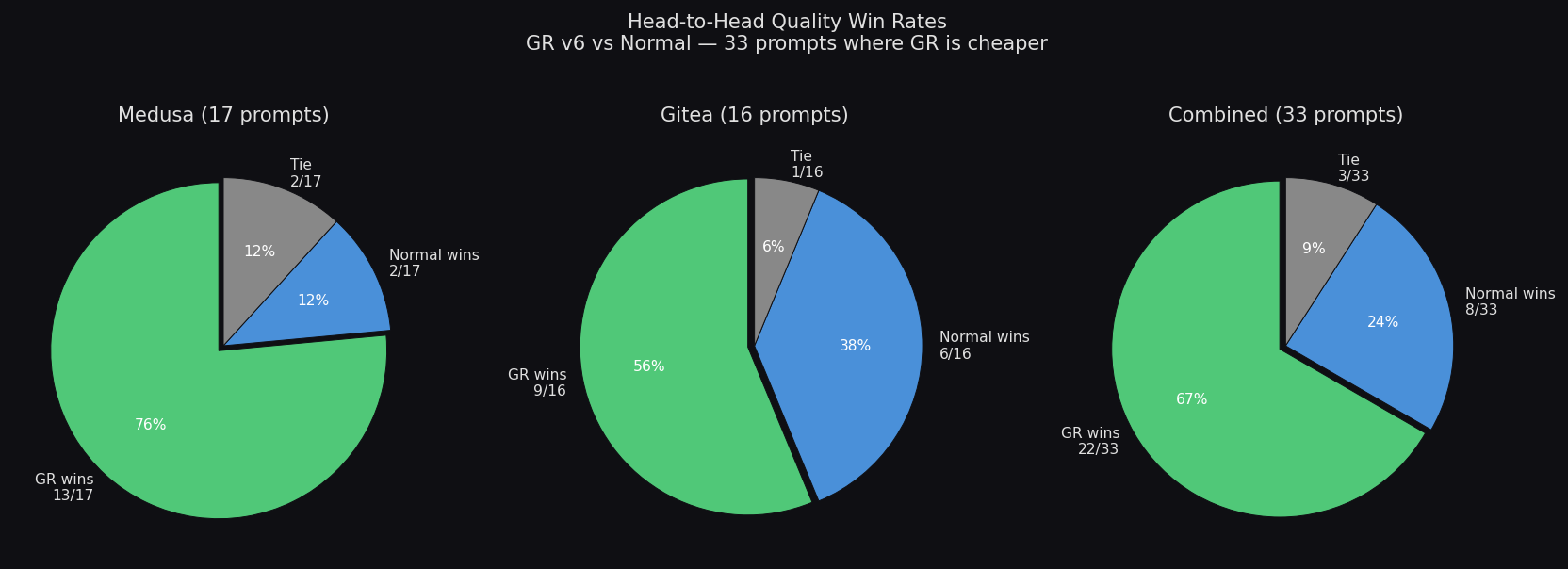
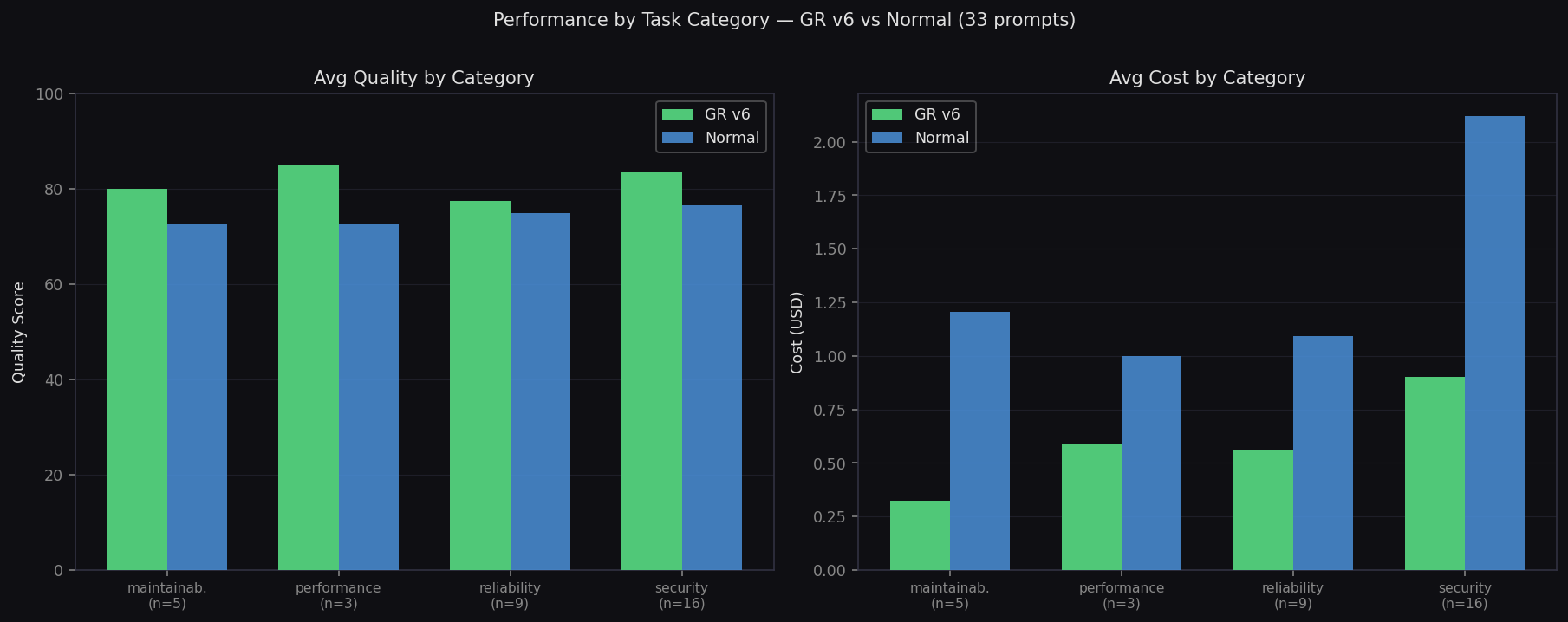
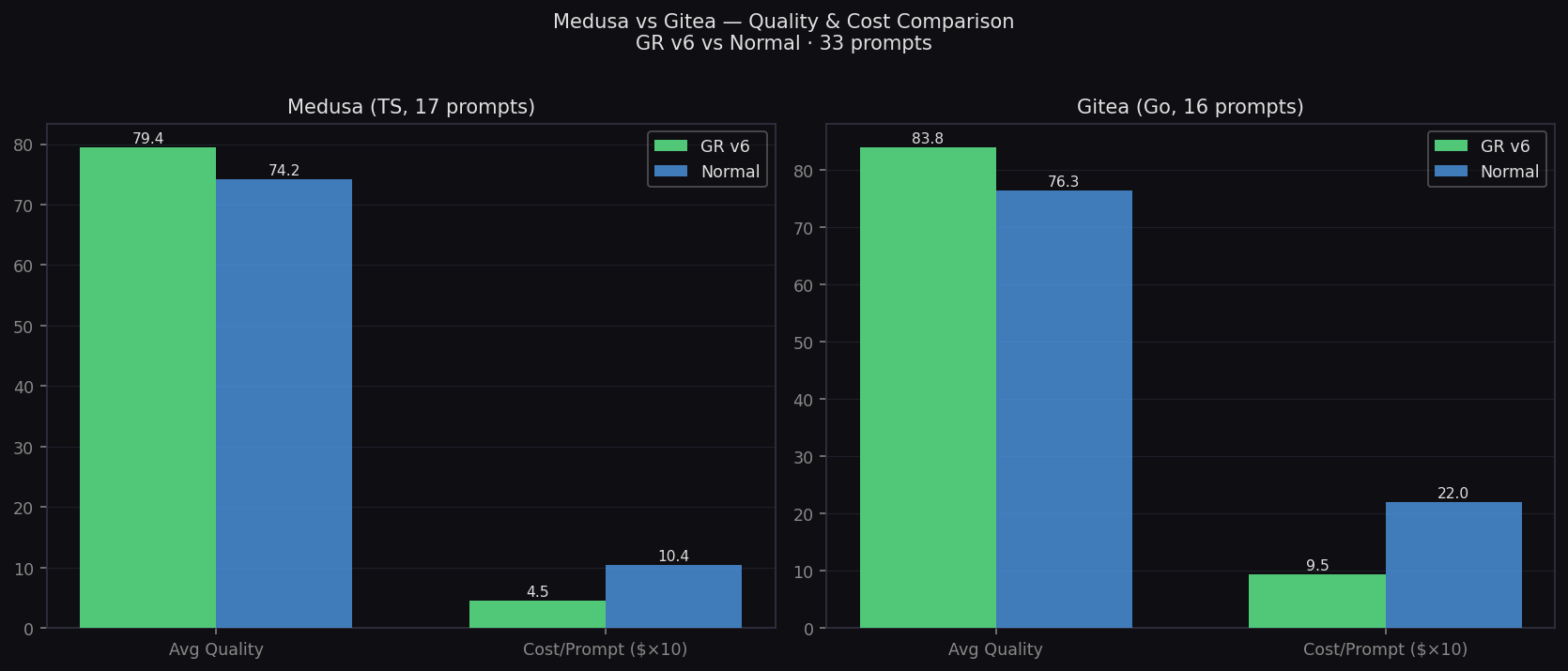
Medusa (TypeScript) — 17 prompts
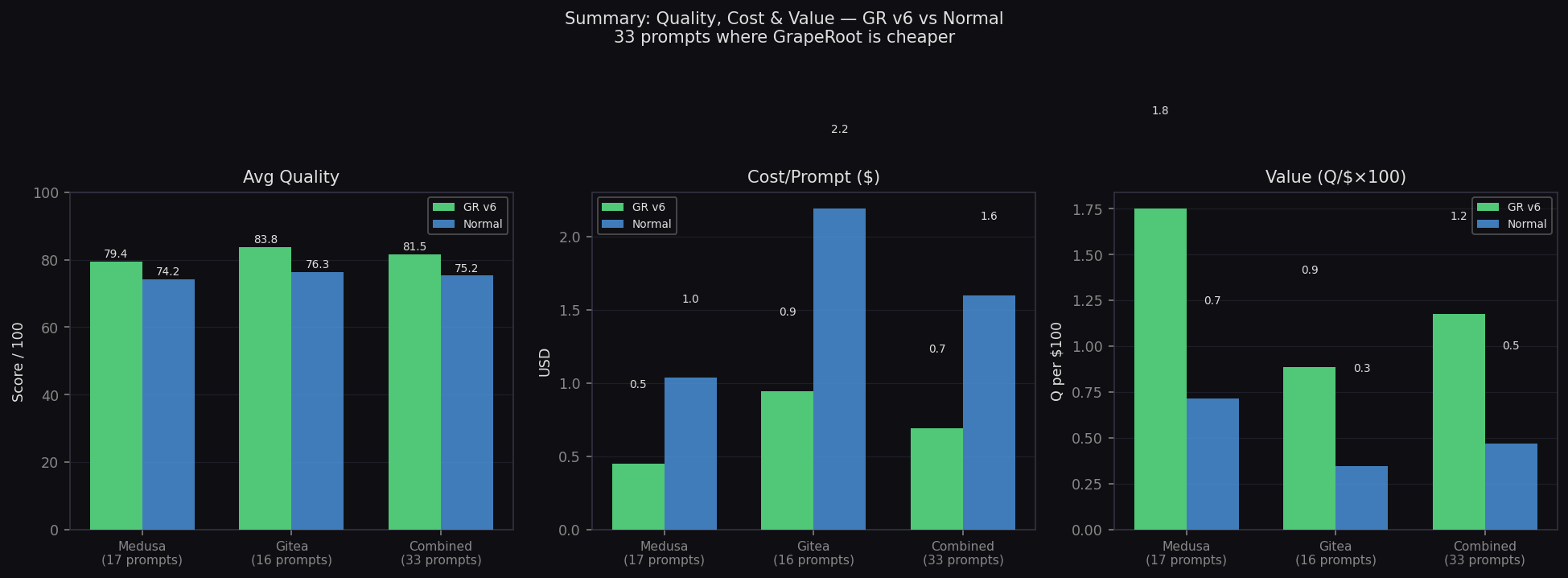
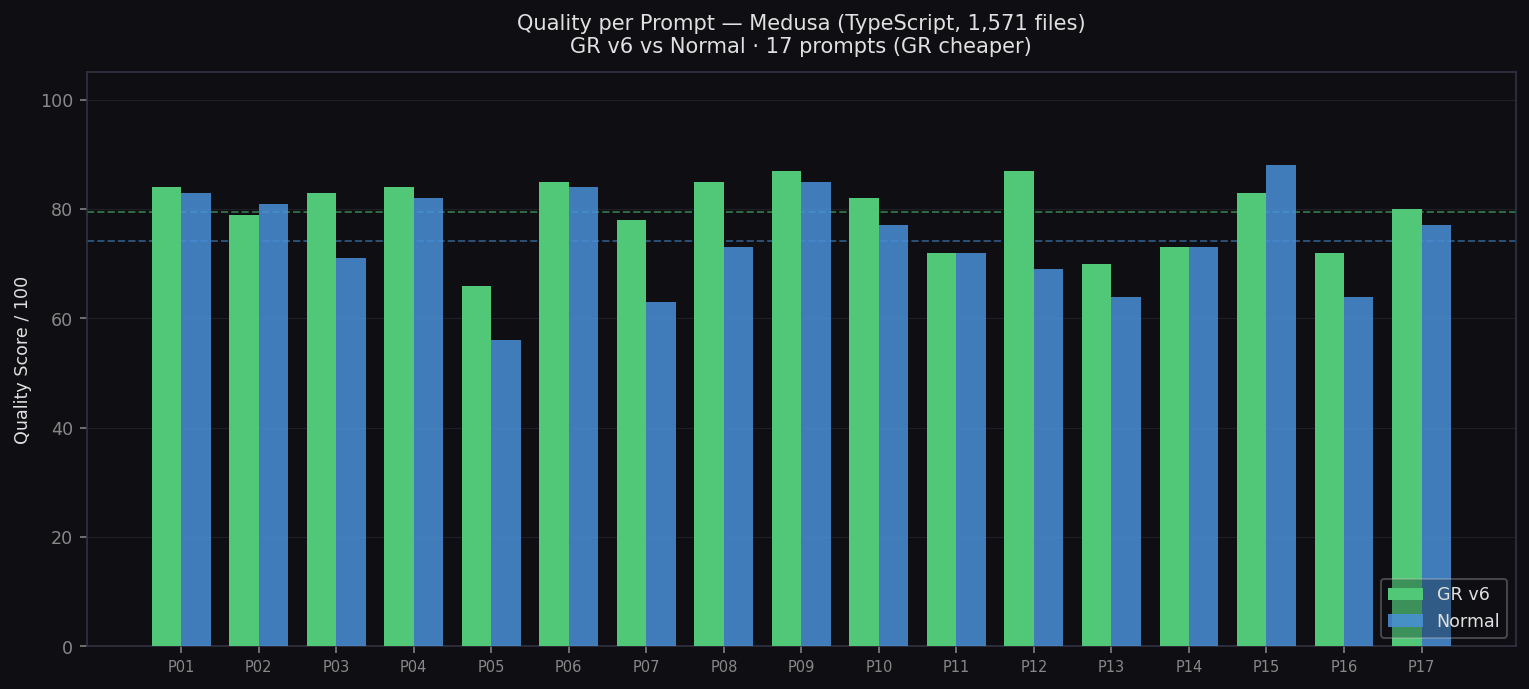
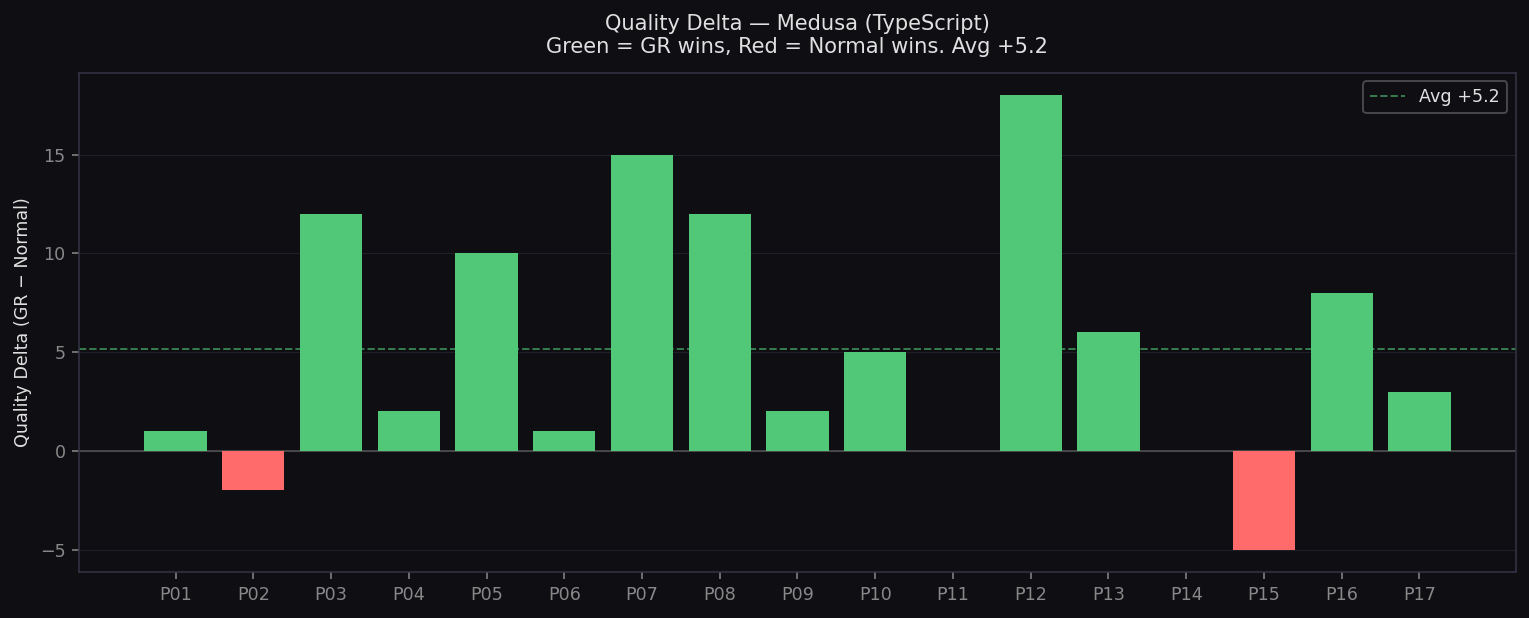
- Quality: 79.4 vs 74.2 (+5.2)
- Cost: $0.45 vs $1.04/prompt
- Quality wins: 15/17 (88%)
- Biggest wins: P6 Dead Exports, P9 Circular Deps
Gitea (Go) — 16 prompts
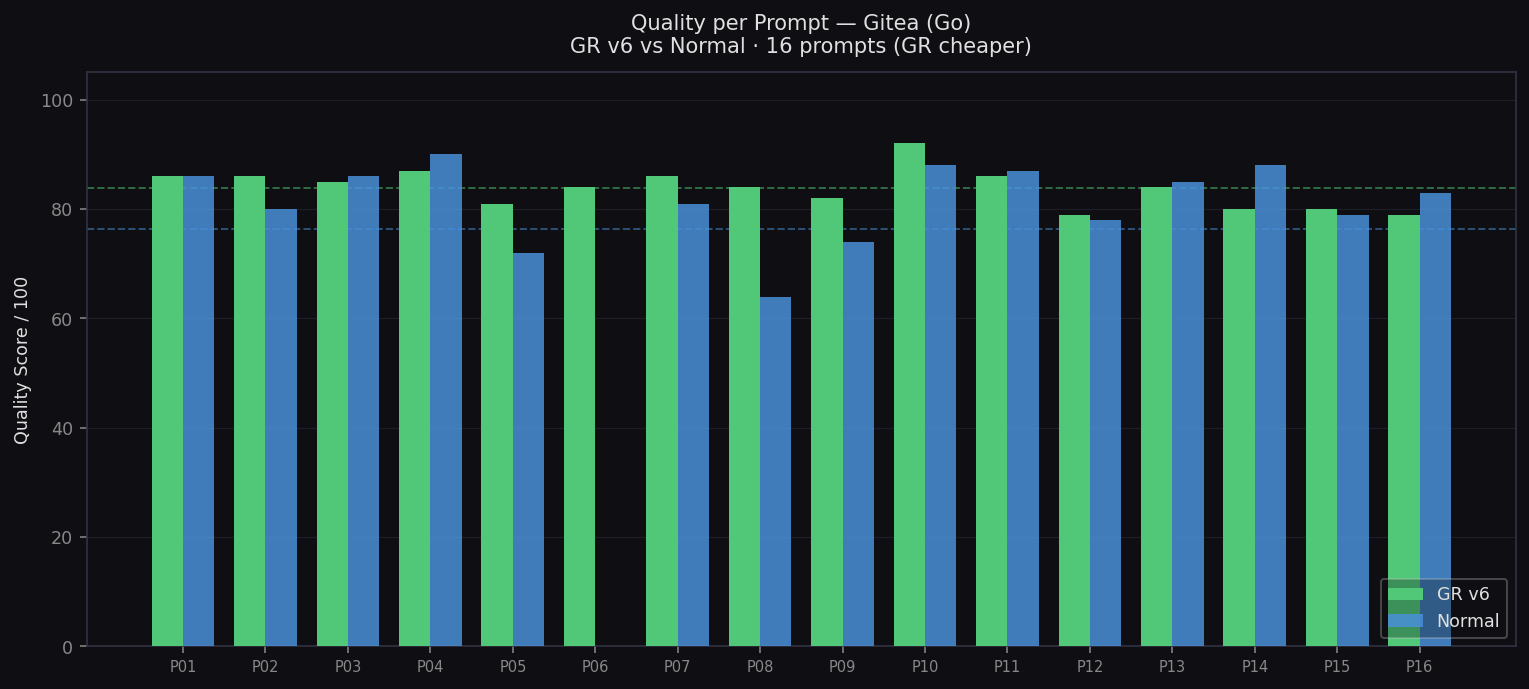
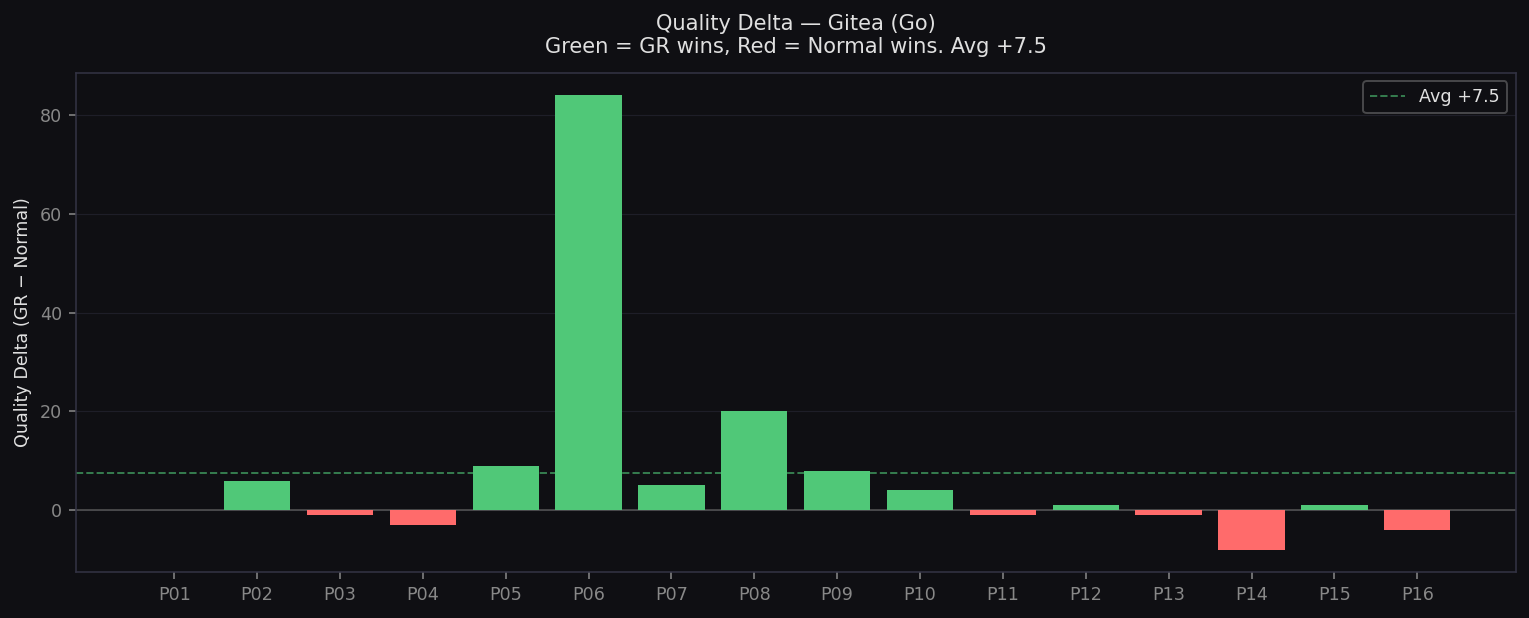
- Quality: 83.8 vs 81.1 (+2.7)
- Cost: $0.95 vs $2.20/prompt
- Quality wins: 10/16 (63%)
- Biggest wins: P8 CSRF ($1.53 vs $5.27), P30 Input Validation ($2.15 vs $6.49)
Featured Chart
Analytics — 16 Charts
Summary: Quality, Cost & Value
Side-by-side across Medusa, Gitea, and Combined
Quality per Prompt — Medusa
GR v6 vs Normal across 17 TypeScript audit prompts
Quality per Prompt — Gitea
GR v6 vs Normal across 16 Go audit prompts
Head-to-Head Win Rates
GR wins 75% of prompts (25/33) — 88% on Medusa, 63% on Gitea
Quality Delta — Medusa
Per-prompt improvement: green = GR wins, red = Normal wins. Avg +3.9
Quality Delta — Gitea
Per-prompt improvement on Go codebase
Cost Savings Summary
57% cheaper overall — $29.91 saved across 33 prompts
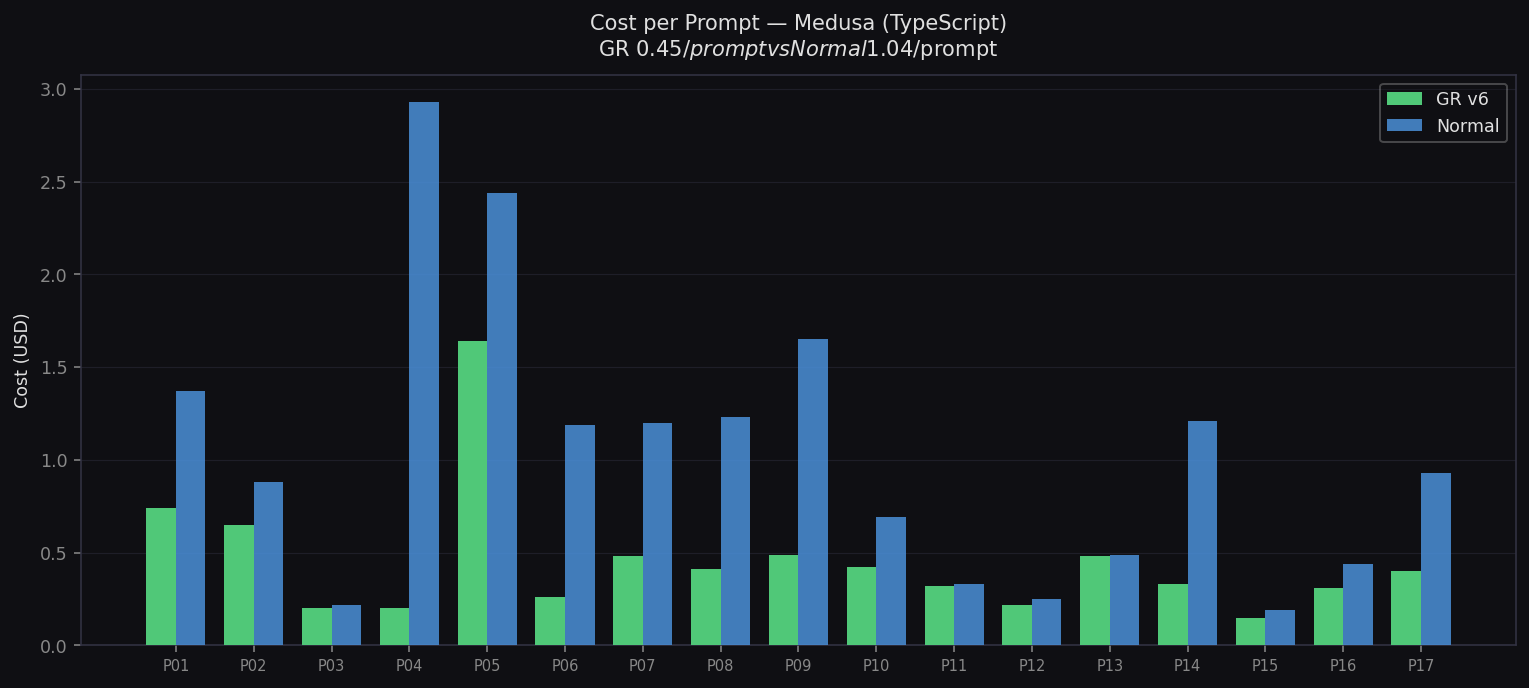
Cost per Prompt — Medusa
GR $0.45/prompt vs Normal $1.04/prompt (57% cheaper)
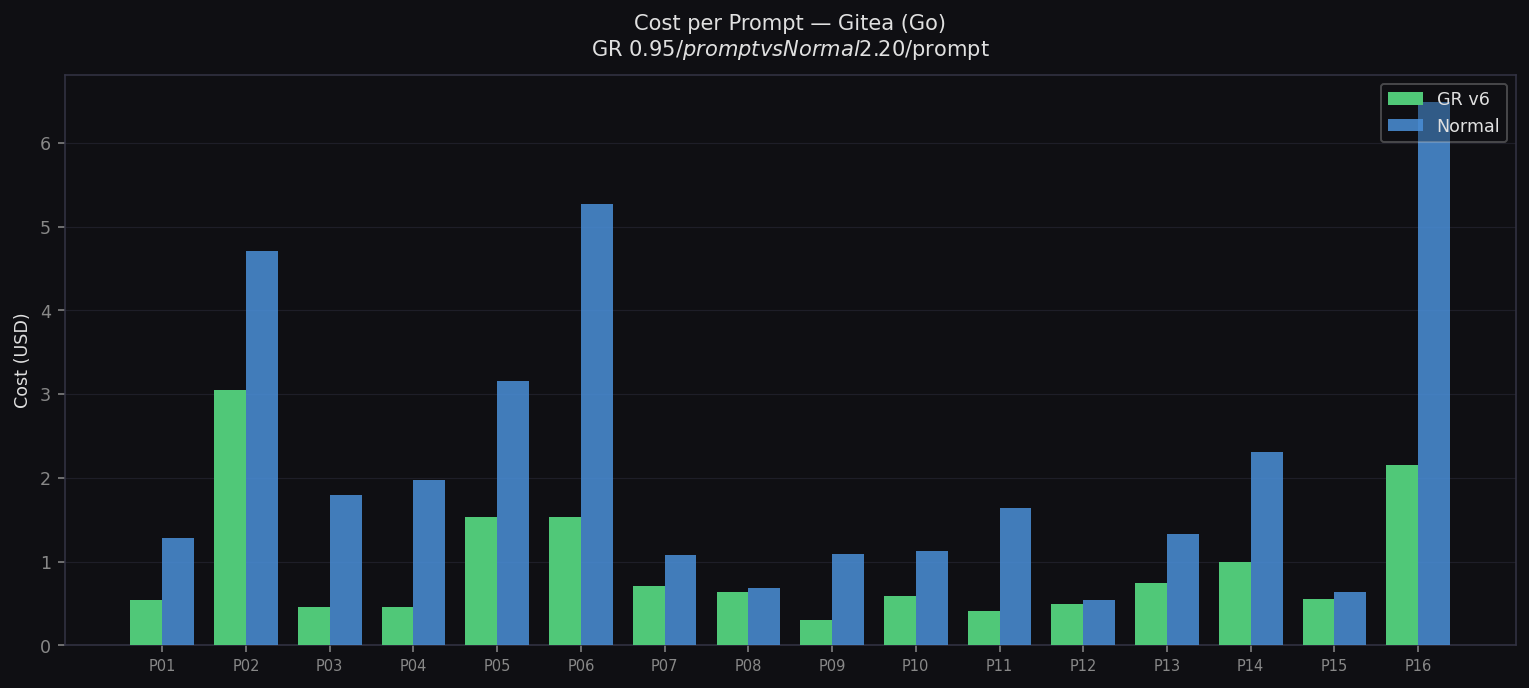
Cost per Prompt — Gitea
GR $0.93/prompt vs Normal $2.18/prompt (57% cheaper)
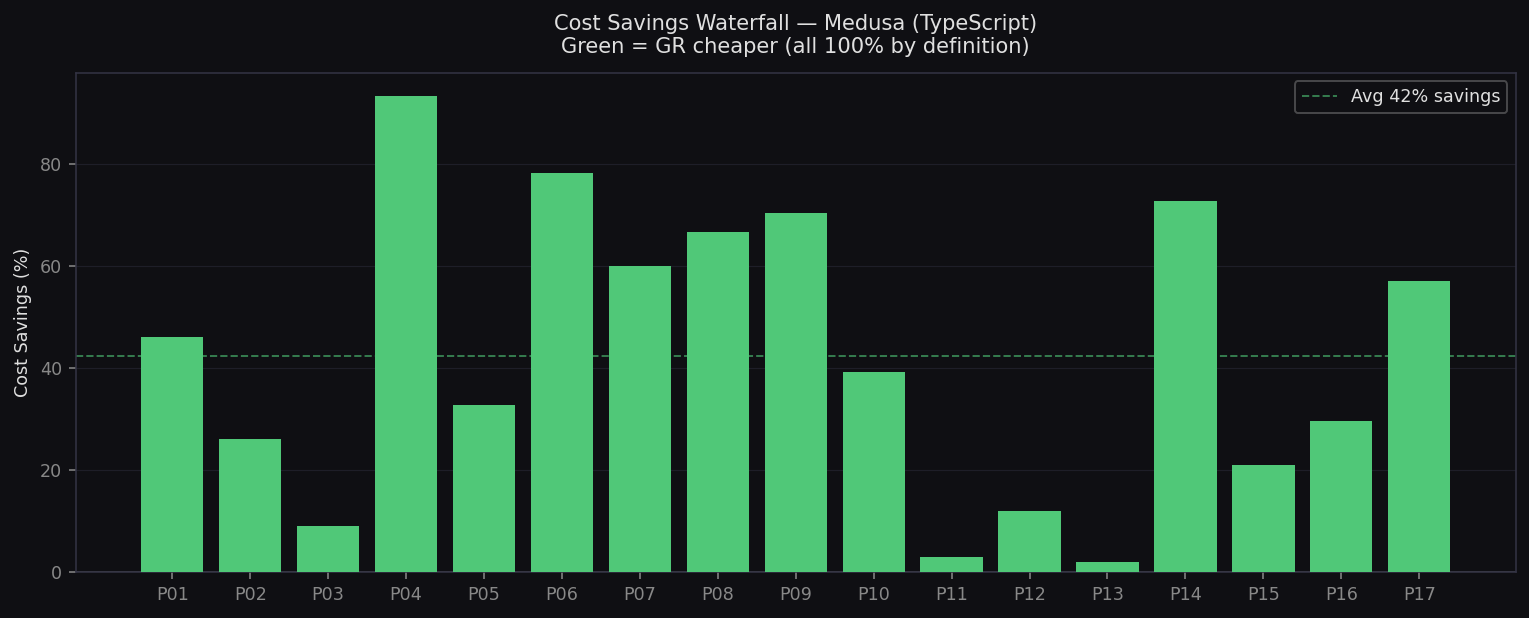
Cost Savings Waterfall — Medusa
Per-prompt cost savings across 17 TypeScript prompts
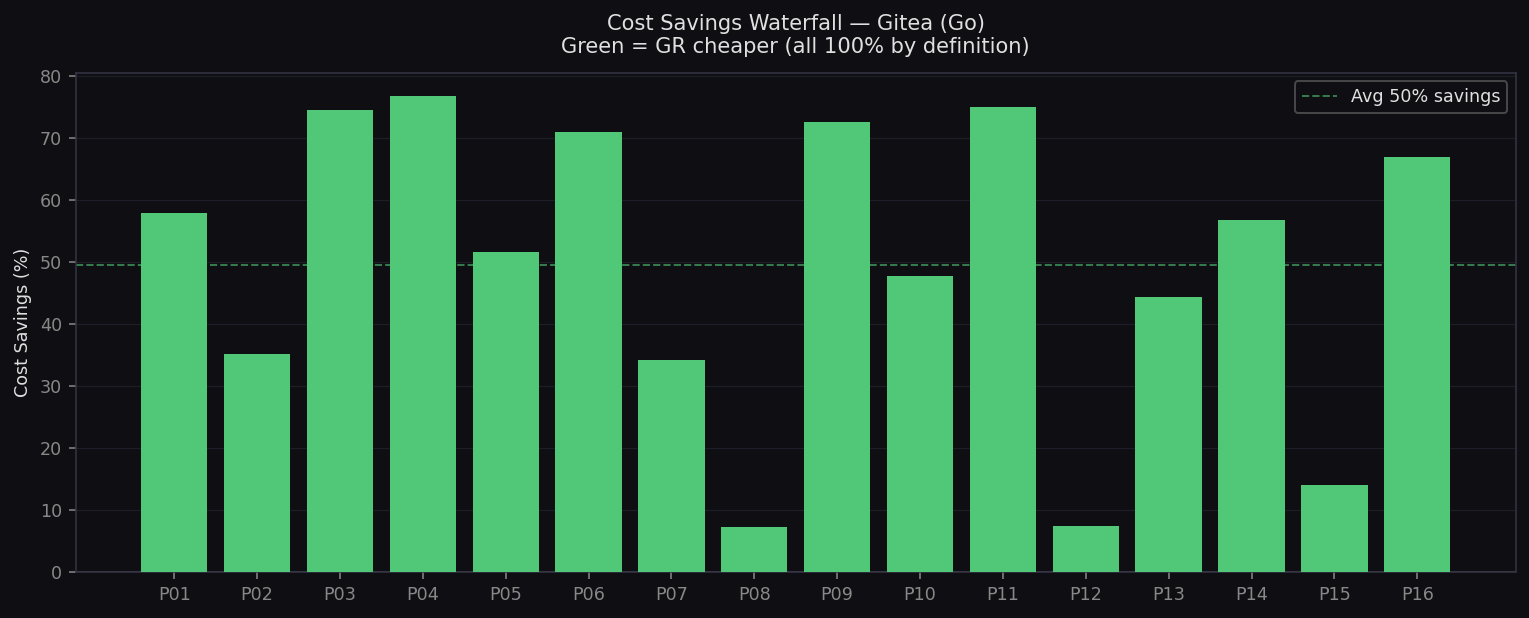
Cost Savings Waterfall — Gitea
Per-prompt savings on Go codebase
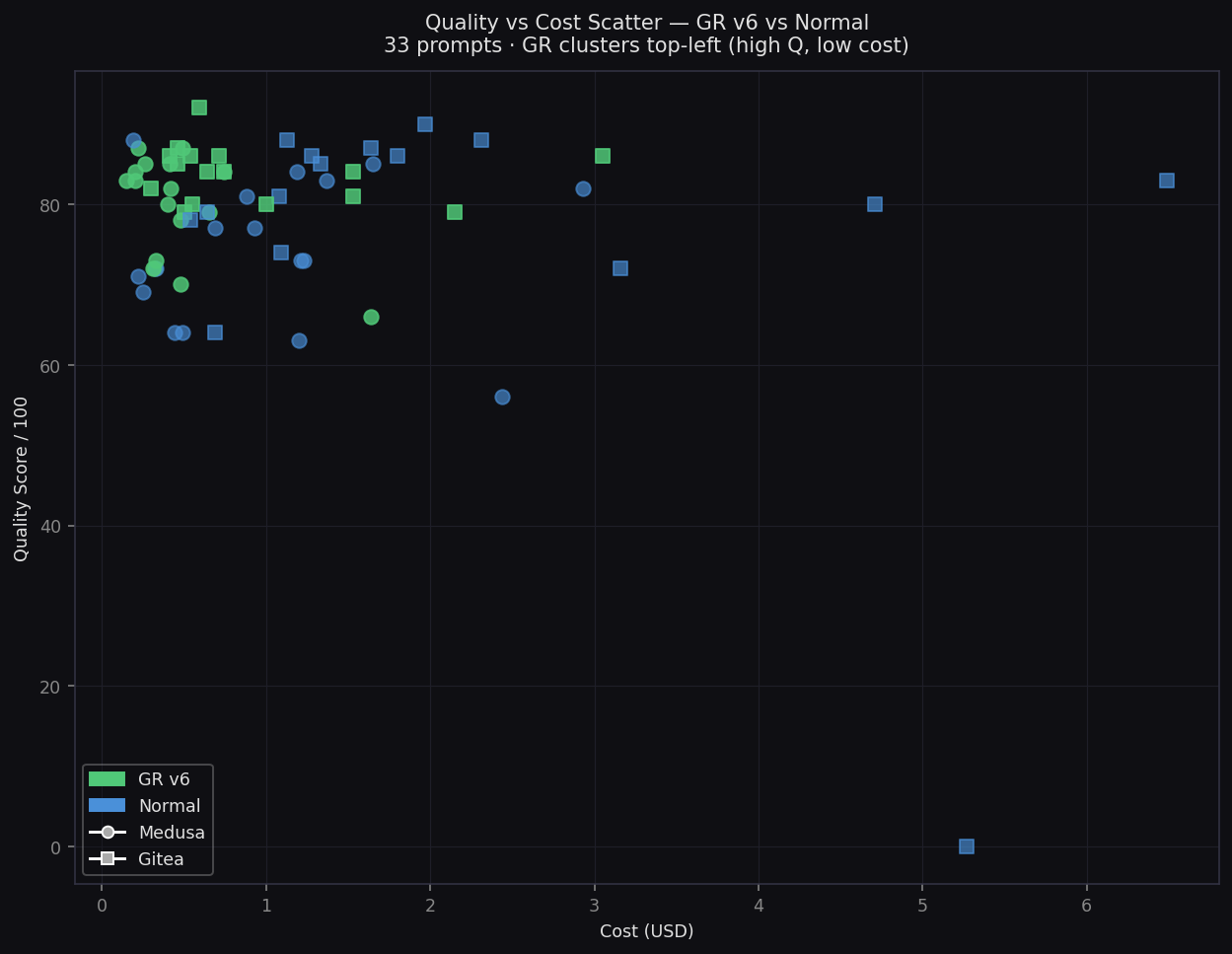
Quality vs Cost Scatter
Every prompt plotted — GR clusters top-left (high Q, low cost)
Performance by Task Category
Quality and cost breakdown across security, performance, reliability, maintainability
Targeted vs Exhaustive Tasks
GR excels on both task types — bigger wins on exhaustive
Quality Score Distribution
Box plots showing GR has higher median and tighter spread